키보드에서 Windows Key + X를 누른 뒤 장치 관리자(Device Manager)를 클릭합니다. 휴먼 인터페이스 장치(Human Interface Devices) 필드를 확장합니다. HID 규격 터치 스크린을 마우스 오른쪽 버튼으로 클릭 합니다. 사용 안 함을 클릭합니다.
형태소 분석기는 형태소를 분석해주는 프로그램이다.konlpy는 Python에서 사용할 수 있는 오픈소스 형태소 분석기로, 기존에 공개된 꼬꼬마(Kkma), 코모란(Komoran), 한나눔(Hannanum), 트위터(Twitter), 메카브(Mecab)를 한 번에 설치하고 동일한 방법으로 쓸 수 있게 해준다. (단 메카브는 윈도에서 사용할 수 없다)
# 도커 기반일 경우
> FROM python:3
> ENV JAVA_HOME /usr/lib/jvm/java-1.7-openjdk/jre
> RUN apt-get update && apt-get install -y g++ default-jdk
> RUN pip install konlpy
> # Write left part as you want
# 다운로드
https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences
> vi amazonpkl.py
import pandas as pd
df = pd.read_csv('amazon_cells_labelled.txt', sep="\t", header=None)
content = df[0]
sentiment = df[1]
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english',
lowercase=True,
max_features=1000)
tdm = tfidf.fit_transform(content)
print(tfidf.get_feature_names()[-10:])
import joblib
with open('amazon.pkl', 'wb') as f:
joblib.dump(
{'vectorizer': tfidf, 'tdm': tdm, 'sentiment': sentiment},
f
)
> python amazonpkl.py
> vi amazonpklinfo.py
import joblib
with open('amazon.pkl', 'rb') as f:
data = joblib.load(f)
locals().update(data)
count = tdm.sum(axis=0)
import pandas as pd
word_count = pd.DataFrame({
'단어': vectorizer.get_feature_names(),
'빈도': count.flat})
print(word_count.tail())
> python amazonpklinfo.py
tar xvfz mecab-ko-dic-2.1.1-20180720.tar.gz
cd mecab-ko-dic-2.1.1-20180720
./configure
make
sudo make install
# 아래 디렉토리에 설치
/usr/local/lib/mecab/dic/mecab-ko-dic
# Jupyter 에서 사용 가능
from konlpy.tag import Mecab
mecab = Mecab()
4) 테스트
$ mecab -d /usr/local/lib/mecab/dic/mecab-ko-dic
mecab-ko-dic은 MeCab을 사용하여, 한국어 형태소 분석을 하기 위한 프로젝트입니다.
mecab SL,*,*,*,*,*,*,*
- SY,*,*,*,*,*,*,*
ko SL,*,*,*,*,*,*,*
- SY,*,*,*,*,*,*,*
dic SL,*,*,*,*,*,*,*
은 JX,*,T,은,*,*,*,*
MeCab SL,*,*,*,*,*,*,*
을 JKO,*,T,을,*,*,*,*
사용 NNG,행위,T,사용,*,*,*,*
하 XSV,*,F,하,*,*,*,*
여 EC,*,F,여,*,*,*,*
, SC,*,*,*,*,*,*,*
한국어 NNG,*,F,한국어,Compound,*,*,한국/NNG/*+어/NNG/*
형태소 NNG,*,F,형태소,Compound,*,*,형태/NNG/*+소/NNG/*
분석 NNG,행위,T,분석,*,*,*,*
을 JKO,*,T,을,*,*,*,*
하 VV,*,F,하,*,*,*,*
기 ETN,*,F,기,*,*,*,*
위한 VV+ETM,*,T,위한,Inflect,VV,ETM,위하/VV/*+ᆫ/ETM/*
프로젝트 NNG,*,F,프로젝트,*,*,*,*
입니다 VCP+EF,*,F,입니다,Inflect,VCP,EF,이/VCP/*+ᄇ니다/EF/*
. SF,*,*,*,*,*,*,*
EOS
- 표층형 : 단어명
- 1785,3543,4267 : 좌문맥ID, 우문맥ID, 단어비용 (자동 생성 처리로 입력)
- 품사태그 : 품사 입력 (mecab-ko-dic 품사 태그를 참조하여 입력)
- 의미분류 : 인명 또는 지명 또는 *
- F : 받침유무 (원 단어의 끝 글자 받침 유무로 T, F 입력)
- 읽기 : 발음 (원 단어의 발음을 입력)
- 타입 : inflected, compound, Preanalysis, *
- 첫번째 품사, 마지막 품사 : 기분석으로 나눠지는 토큰에 대한 각 품사 입력 (mecab-ko-dic 품사 태그를 참조하여 입력)
- 원형 : 토큰 들로 나눠지는 부분 +로 입력 ( 각 토큰 : 표층형/품사태그/의미분류 )
- 인덱스표현 : 토큰 들로 나눠지는 부분 +로 입력 ( 각 토큰: 표층형/품사태그/의미부류/PositionIncrementAttribute/PositionLengthAttribute)
1. 사전 등록
- mecab-ko-dic 설치 위치로 가서 nnp.csv에 사용자 사전 입력
>> cd ~/mecab-ko-dic-2.1.1-20180720/user-dic
>> vi nnp.csv
다음 형태로 입력
구르미그린달빛,0,0,0,NNP,*,T,구르미그린달빛,*,*,*,*
고프로,0,0,0,NNP,*,F,고프로,*,*,*,*
썸즈업,0,0,0,NNP,*,T,썸즈업,*,*,*,*
썬팍,0,0,0,NNP,*,T,썬팍,*,*,*,*
- 적용 전 테스트
- 사전 적용
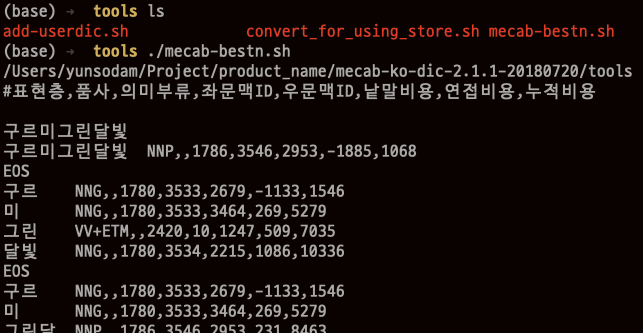
tools>> ./add-userdic.sh
mecab-ko-dic-2.1.1-20180720 >> make install
(base) ➜ mecab-ko-dic-2.1.1-20180720 cd tools
(base) ➜ tools ./add-userdic.sh
(base) ➜ mecab-ko-dic-2.1.1-20180720 make install
generating userdic...
nnp.csv
.
.
.
emitting matrix : 100% |###########################################|
done!
echo To enable dictionary, rewrite /usr/local/etc/mecabrc as \"dicdir = /usr/local/lib/mecab/dic/mecab-ko-dic\"
To enable dictionary, rewrite /usr/local/etc/mecabrc as "dicdir = /usr/local/lib/mecab/dic/mecab-ko-dic"
(base) ➜ tools
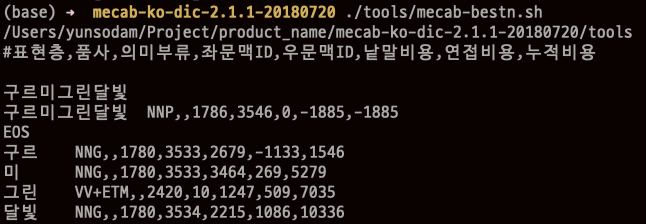
- 사전 적용 후 테스트
사전은 적용 되었지만 등록한 단어의 우선순위(단어비용)가 낮아서,원하지 않는 모양으로 분해 되는 것을 확인함. (단어비용을 낮추면 검색 우선순위가 높아짐) 현재 적용된 단어 비용
sudo groupadd mysql sudo useradd -g mysql mysql cd /usr/local sudo tar -zxvpf mariadb-10.6.4-linux-systemd-x86_64.tar.gz sudo ln -s mariadb-10.6.4-linux-systemd-x86_64 mysql
3) vi /etc/my.cnf
[client-server] port=3306
# This will be passed to all MariaDB clients [client]
# The MariaDB server [mysqld] # Directory where you want to put your data datadir=/usr/local/mysql/data
character-set-server = utf8mb4 init_connect = SET collation_connection = utf8mb4_general_ci init_connect = SET NAMES utf8mb4
# This is the prefix name to be used for all log, error and replication files log-basename=mariadb
4) 초기화
cd /usr/local/mysql sudo ./scripts/mysql_install_db --user=mysql
5) 디렉토리 권한 변경
/usr/local/mysql> sudo chown -R root . /usr/local/mysql> sudo chown -R mysql data
6) 서버 기동
sudo ./bin/mysqld_safe --user=mysql & or sudo ./bin/mysqld_safe --defaults-file=~/.my.cnf --user=mysql &
7) 오류발생시
# ERROR 2002 (HY000): Can't connect to local server through socket '/var/run/mysqld/mysqld.sock' (2)
Switch to unix_socket authentication [Y/n] n Change the root password? [Y/n] Y New password: "ROOT 비번 설정" Re-enter new password: Password updated successfully! Remove anonymous users? [Y/n] Y Disallow root login remotely? [Y/n] n Remove test database and access to it? [Y/n] n Reload privilege tables now? [Y/n] Y ... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MariaDB installation should now be secure.
Thanks for using MariaDB!
10)
mysql> select host, user from mysql.user;
mysql> create user ml@localhost identified by 'ml';
mysql> flush privileges;
mysql> grant all privileges on *.* to ml@'localhost' identified by 'ml';
mysql> grant all privileges on *.* to ml@'%' identified by 'ml'; mysql> flush privileges;
11)
show variables like '%set%';
SELECT schema_name, default_character_set_name, DEFAULT_COLLATION_NAME FROM information_schema.SCHEMATA ;