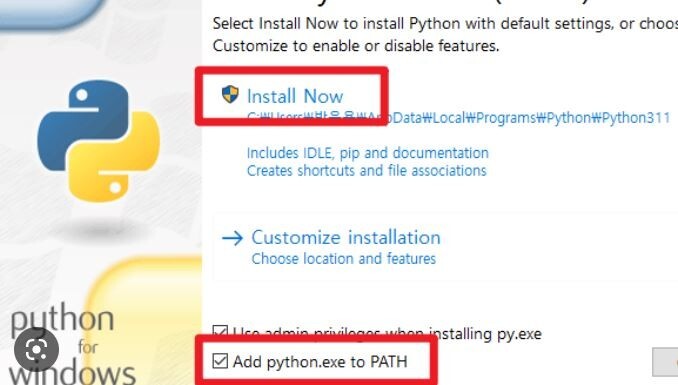
주소 입력란 1은 도로 번호와 이름입니다. 주소 입력란 2는 도시, 주 약어 및 우편번호입니다. 12345 무슨무슨 (도)로 시 (*) : 주 (*) : 우편 번호 영문주소 address line1, 2 쓰는 법 : https://barrogo.tistory.com/106
1. json 파일 없음 [ec2-user@ip-172-31-19-40 Auto-GPT]$ python3 -m autogpt Warning: The file 'AutoGpt.json' does not exist. Local memory would not be saved to a file. Welcome to Auto-GPT! Enter the name of your AI and its role below. Entering nothing will load defaults. Name your AI: For example, 'Entrepreneur-GPT' AI Name: 해결법 VScode 실행. AutoGpt.json 빈 파일 만들어 ai test 폴더에 저장 https://blog.finxter.com/fixed-warning-the-file-autogpt-json-does-not-exist-local-memory-would-not-be-saved-to-a-file/
2. AutoGpt 실행 시 Colorama Module 이 없음 설치하세요! >> chatgpt 한테 이거 해결해줘 쓰고 오류 Ctrl+C , Ctrl+V
3. -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-= SYSTEM: Command evaluate_code returned: Error: The model: `gpt-4` does not exist
Auto gpt 한국인 디스코드 서버 개설했습니다. What's Auto Gpt Discord? 1. 설치 오류 서로 도와주기 2. AutoGpt 로 뭐 만드는지 공유해요. 3. 다른 사람들 작업물 돕기 4. 프로젝트 참여 5. Auto gpt 정보, AI 비즈니스 아이디어 부자되기 함께해요
기계 학습 모델을 구축하고 훈련하는 과정에서 각 실험의 결과를 추적하는 것은 매우 중요합니다. 딥 러닝 모델의 경우 TensorBoard는 훈련 성능을 기록하고, 기울기를 추적하고, 모델을 디버그하는 등 매우 강력한 도구입니다. 또한 관련 소스 코드를 추적해야합니다. Jupyter Notebook은 버전을 지정하기가 어렵지만 git과 같은 VCS를 사용하여 도움을 줄 수 있습니다. 그러나 실험 컨텍스트, 하이퍼 파라미터 선택, 실험에 사용 된 데이터 세트, 결과 모델 등을 추적하는 데 도움이되는 도구도 필요합니다. MLflow는 웹 사이트에 명시된대로 해당 목적을 위해 명시 적으로 개발되었습니다.
MLflow는 실험, 재현성 및 배포를 포함하여 ML 수명주기를 관리하기위한 오픈 소스 플랫폼입니다.
이를 위해 MLflow는MLflow Tracking실험 / 실행을 추적 할 수있는 웹 서버 인 구성 요소 를 제공합니다 .
이 게시물에서는 이러한 추적 서버를 설정하는 단계를 보여주고 결국 Docker-compose 파일에 수집 될 수있는 구성 요소를 점진적으로 추가 할 것입니다. Docker 접근 방식은 MLflow를 원격 서버 (예 : EC2)에 배포해야하는 경우 특히 편리합니다. 새 서버가 필요할 때마다 서버를 직접 구성 할 필요가 없습니다.
기본 로컬 서버
MLflow 서버를 설치하는 첫 번째 단계는 간단하며 python 패키지 만 설치하면됩니다. 나는 파이썬이 컴퓨터에 설치되어 있고 가상 환경을 만드는 데 익숙하다고 가정합니다. 이를 위해 pipenv보다 conda가 더 편리하다고 생각합니다.
이제 실험과 실행을 추적 할 실행중인 서버가 있지만 더 나아가려면 아티팩트를 저장할 서버를 지정해야합니다. 이를 위해 MLflow는 몇 가지 가능성을 제공합니다.
아마존 S3
Azure Blob 저장소
구글 클라우드 스토리지
FTP 서버
SFTP 서버
NFS
HDFS
(mlflow-env)$ mlflow server — default-artifact-root s3://mlflow_bucket/mlflow/ — host 0.0.0.0
MLflow는 시스템의 IAM 역할, ~ / .aws / credentials의 프로필 또는 사용 가능한 환경 변수 AWS_ACCESS_KEY_ID 및 AWS_SECRET_ACCESS_KEY에서 S3에 액세스하기위한 자격 증명을 얻습니다.
— h ttps : //www.mlflow.org/docs/latest/tracking.html
따라서 더욱 실용적인 방법은 특히 AWS EC2 인스턴스에서 서버를 실행하려는 경우 IAM 역할을 사용하는 것입니다. 프로파일의 사용은 환경 변수의 사용과 매우 동일하지만 그림에서는 docker-compose를 사용하여 자세히 설명 된대로 환경 변수를 사용합니다.
백엔드 저장소 사용
SQLite 서버
따라서 추적 서버는 S3에 아티팩트를 저장합니다. 그러나 하이퍼 파라미터, 주석 등은 여전히 호스팅 시스템의 파일에 저장됩니다. 파일은 틀림없이 좋은 백엔드 저장소가 아니며 우리는 데이터베이스 백엔드를 선호합니다. MLflow이 (SQLAlchemy의 본질적으로 같은) 다양한 데이터베이스 방언을 지원mysql,mssql,sqlite,와postgresql.
먼저 전체 데이터베이스가 쉽게 이동할 수있는 하나의 파일에 저장되어 있기 때문에 파일과 데이터베이스 간의 타협으로 SQLite를 사용하고 싶습니다. 구문은 SQLAlchemy와 동일합니다.
Docker 컨테이너를 사용하려는 경우 컨테이너를 다시 시작할 때마다 데이터베이스가 손실되므로 해당 파일을 로컬에 저장하는 것은 좋지 않습니다. 물론 EC2 인스턴스에 볼륨과 EBS 볼륨을 계속 마운트 할 수 있지만 전용 데이터베이스 서버를 사용하는 것이 더 깨끗합니다. 이를 위해 MySQL을 사용하고 싶습니다. 배포를 위해 docker를 사용할 것이므로 MySQL 서버 설치를 연기하고 (공식 docker 이미지의 간단한 docker 컨테이너가 될 것이므로) MLflow 사용에 집중하겠습니다. 먼저 MySQL과 상호 작용하는 데 사용할 Python 드라이버를 설치해야합니다.pymysql설치가 매우 간단하고 매우 안정적이며 잘 문서화되어 있기 때문에 좋아 합니다. 따라서 MLflow 서버 호스트에서 다음 명령을 실행합니다.
이제 모든 설정이 완료되었으므로 모든 것을 도커 작성 파일에 모을 시간입니다. 그런 다음 명령만으로 MLflow 추적 서버를 시작할 수 있으므로 매우 편리합니다. docker-compose 파일은 세 가지 서비스로 구성됩니다. 하나는 백엔드, 즉 MySQL 데이터베이스, 하나는 역방향 프록시 용, 다른 하나는 MLflow 서버 자체 용입니다. 다음과 같이 보입니다.
version: '3.3'
services:
db:
restart: always
image: mysql/mysql-server:5.7.28
container_name: mlflow_db
expose:
- "3306"
networks:
- backend
environment:
- MYSQL_DATABASE=${MYSQL_DATABASE}
- MYSQL_USER=${MYSQL_USER}
- MYSQL_PASSWORD=${MYSQL_PASSWORD}
- MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD}
volumes:
- dbdata:/var/lib/mysql
web:
restart: always
build: ./mlflow
image: mlflow_server
container_name: mlflow_server
expose:
- "5000"
networks:
- frontend
- backend
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
command: mlflow server --backend-store-uri mysql+pymysql://${MYSQL_USER}:${MYSQL_PASSWORD}@db:3306/${MYSQL_DATABASE} --default-artifact-root s3://mlflow_bucket/mlflow/ --host 0.0.0.0
먼저 주목할 점은 프런트 엔드 (MLflow UI)를 백엔드 (MySQL 데이터베이스)로 분리하기 위해 두 개의 사용자 지정 네트워크를 구축했습니다.web서비스, 즉 MLflow 서버 만 둘 다와 통신 할 수 있습니다. 둘째, 컨테이너가 다운 될 때 모든 데이터가 손실되는 것을 원하지 않으므로 MySQL 데이터베이스의 콘텐츠는dbdata. 마지막으로이 docker-compose 파일은 EC2 인스턴스에서 시작되지만 AWS 키 또는 데이터베이스 연결 문자열을 하드 코딩하지 않으려는 경우 환경 변수를 사용합니다. 이러한 환경 변수는 호스트 시스템에 직접 위치하거나.envdocker-compose 파일과 동일한 디렉토리에 있는 파일 내에있을 수 있습니다 . 남은 것은 컨테이너를 구축하고 실행하는 것입니다.
$ docker-compose up -d --build
그리고 그게 전부입니다 ! 이제 팀간에 공유 할 수있는 완벽하게 실행되는 원격 MLflow 추적 서버가 있습니다. 이 서버는 docker-compose 덕분에 하나의 명령으로 어디서나 쉽게 배포 할 수 있습니다.
MLproject라는 파일이 존재하는데, 이 파일을 통해 이 프로젝트가 MLflow Project 임을 알 수 있다. MLflow Projet 는mlflow run명령어로 실행이 가능하다. 위의 경우mlflow run sklearn_logistic_regression으로 실행할 수 있다.
MLProject 살펴보기
MLflow Project 를mlflow run으로 실행할 때 무엇을 어떻게 실행할 것인지를 알아야하는데, 이에 대한 내용을MLproject파일이 담고있다.
간단한 예시를 보자. 다음은examples/sklearn_elasticnet_wine/MLproject파일의 내용이다.
이 MLProject 를 실행할 때 conda 환경을 만든 뒤 실행하게 되는데, 이 때 참고할 conda 환경에 대한 파일이름을 값으로 가진다. 여기서는 이 프로젝트 내conda.yaml에 이 설정 값들이 있다.
conda가 아닌 docker를 사용할 수 있는데, 이 때docker_env라는 키를 사용하면 된다. 이에 대한 내용은 아래에서 다시 설명하겠다.
entry_points
mlflow run으로 실행할 때-e옵션으로 프로젝트 실행에 여러 진입점을 둘 수 있는데, 이 때 사용되는 값이다.
예를 들면, 위의 경우mlflow run -e main sklearn_elastic_wine으로main이라는 진입점으로 실행할 수 있다.
위 명령어가 실행되면python train.py {alpha} {l1_ratio}명령어를 실행한다. 이 때{alpha}와{l1_ratio}는 위mlflow run시 받는 파라미터 값이다. 이는parameters에 정의가 되어있다.
다시 정리해보면 위와 같이 정의된 MLflow Project는 다음 명령어로 실행할 수 있다. (코드에서는mlflow.projects.run()명령어로 실행할 수 있다. 이에 대한 내용은여기를 참고하자.)
$ mlflow run -e main sklearn_elastic_wine -P alpha=0.1 -P l1_ratio=0.5
이 명령어는 다시 내부적으로 아래 명령어를 실행하게 된다.
$ python train.py 0.1 0.5
Docker 환경 사용하여 실행하기
위MLproject파일 내에서conda_env를 사용하였다. 이럴 경우 MLflow Project를 실행시키는 환경에 conda가 미리 깔려있어야 실행이 가능하다. conda가 깔려있지 않으면mlflow run에서 에러를 뱉을 것이다. (--no-conda옵션을 주는 경우도 있지만, 이럴 경우 또virtuanlenv등으로 가상 환경을 세팅하고 필요한 라이브러리르 일일이 설치해주어야 해서 번거롭다.)
conda를 쓰지 않고 docker 컨테이너 환경으로 실행이 가능한데 이 방법을 살펴보자. 이번에도 역시 공식 예제를 활용한다. 다음은examples/docker에 있는 예시다.
# Dockerfile
FROM python:3.8.8-slim-buster
RUN pip install mlflow>=1.0 \
&& pip install numpy \
&& pip install pandas \
&& pip install scikit-learn
# 예제 파일을 그대로 실행하면 오류가 생겨서 약간 손을 보았다.
# 베이스 이미지 수정, 필요없는 패키지 및 버전을 지운 정도다.
# 아마 2년 전 예제라 업데이트가 잘 안된 듯 싶다.
이렇게 실행하면mlflow는mlflow-docker-example이름의 도커 이미지를 찾아 그 위에 mlflow 코드를 실행하는 도커 이미지를 하나 더 만들고 이 이미지를 실행한다. 결과적으로 이미지를 하나 더 만드는 셈이다. 아래 사진을 보면docker-example이라는 이미지가 만들어 진 것을 볼 수 있다.
이미 감이 온 사람은 알겠지만,MLProject의docker_env.image값은 로컬 도커 이미지가 아니여도 된다. Dockerhub나 GCR, ECR 등에 미리 만들어두고 사용해도 된다. 또한 컨테이너 내부의 환경 변수 설정 등도 가능하다. 자세한 내용은여기를 참고하자.
Github에 있는 프로젝트 실행하기
지금까지 로컬에 있는 MLflow Project를 실행했다면 다음처럼 github에 올려둔 MLProject 를 실행시킬 수 있다. 예를 들면 다음과 같다.
mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=0.5 --no-conda
쿠버네티스에서 실행하기
mlflow run을 할 때--backend와--backend-config파라미터 설정으로 MLflow Project를 쿠버네티스 상에서 실행시킬 수 있다. (Job 리소스로 실행된다.) 예를 들면 다음과 같다.
$ mlflow run <project_uri> \
--backend kubernetes \
--backend-config kubernetes_config.json
위 명령어를 실행하게 되면 다음의 과정이 일어난다.
MLflow Project 실행을 도커 이미지로 만든다.
이 이미지를 사용자가 설정해둔 도커 컨테이너 레지스트리에 푸시한다.
쿠버네티스에서 이 이미지를 Job으로 배포한다.
위 명령어가 실행이 되려면 푸시할 도커 이미지 레지스트리와 쿠버네티스 접속 컨텍스트가 필요한데, 이를 위해 MLflow Project 내에 다음과 같은 파일이 있어야 한다.
누군가가 만들어 놓은 MLflow 모델을 보게되면 보통MLmodel을 통해 모델에 대한 정보를 먼저 파악하려고 할 것이다. 그런데 위MLmodel파일만 봐서는 이 모델이 어떤 입력을 받고 어떤 출력을 뱉는지 알수가 없다. 입출력에 대한 정보는 시그니처라고 말하는데, 이를 쉽게 알 수 있도록 시그니처를 추가해주자.
예시 코드는 다음과 같다.
import pandas as pd
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature
iris = datasets.load_iris()
iris_train = pd.DataFrame(iris.data, columns=iris.feature_names)
clf = RandomForestClassifier(max_depth=7, random_state=0)
clf.fit(iris_train, iris.target)
# 입출력 정보를 정해주는 부분. 이런 정보를 시그니처라고 한다.
signature = infer_signature(iris_train, clf.predict(iris_train))
# 위에서 정한 시그니처 값을 인자로 넘긴다.
mlflow.sklearn.log_model(clf, "iris_rf", signature=signature)
위에서는infer_signature()함수를 사용하여 시그니처를 정해주었다. 이 함수는 실제 입력데이터와 출력 데이터를 파라미터로 넘기면, 시그니처를 알아서 추론해준다. 구체적인 모양새는여기를 참고하자.
Model Registry는 MLflow 프로젝트 실행을 통해 나온 결과물인 모델을 저장하는 중앙 집중식 모델 저장소다. MLflow로 모델을 기록했다면, 기록한 모델을 Model Registry에 등록할 수 있고, 등록된 모델은 어디서든 불러올 수 있다.
모델 등록하기
웹 UI로 등록하기
간단하게 모델을 등록해보자. 직전 글에서 사용한 실습을 그대로 이어간다. 웹 서버 (Tracking Server) 에 들어간 뒤, 실행했던 실행(Run)을 클릭하여 들어간다.
실행 상세페이지 하단에 Artifacts 블록이 있고 이 안에Model Register버튼이 있다.
버튼을 클릭하여 다음처럼LinearRegression이라는 이름으로 모델을 등록해주자.
이제 상단 메뉴 중에 Model 탭에 들어가보면 다음처럼 등록된 모델을 확인할 수 있다. 모델을 처음 등록하는 경우Version 1이 자동으로 추가된다.
등록된 모델 하나를 클릭하면 아래처럼 상세 페이지가 나온다.
모델 버전을 누르면 다음처럼 해당 버전의 상세 페이지로 들어갈 수 있다.
Stage항목에서는 이 모델의 스테이지 상태를Staging,Production,Archived중 하나로 바꿀 수 있다. 아무것도 지정하지 않았을 시 기본 값은None이다.
코드에서 등록하기
위처럼 웹 UI가 아니라 코드에서 직접 등록하는 방법도 있다. 총 3가지 방법이 있는데 첫 번째 방법은mlflow.sklearn.log_model()에registered_model_name의 값을 주는 것이다.
이를 직접 확인하기 위해 이전에 실행했던sklearn_logistic_regression예제의train.py를 다음처럼 수정한다.
# sklearn_logistic_regression/train.py
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
# mlflow.sklearn.log_model(lr, "model") # before
mlflow.sklearn.log_model(lr, "model", registered_model_name="LinearRegression") # after
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
바뀐 부분은 딱 한 줄이다.mlflow.sklearn.log_model함수에registered_model_name="LinearRegression"인자를 추가하였다. (이 함수에 자세한 내용은여기서 확인할 수 있다.)
이제 다시 이 MLflow 프로젝트를 실행하자.
$ mlflow run sklearn_logistic_regression --no-conda
로그를 보면LinearRegression이 이미 등록된 모델이므로, 등록된 모델의 새 버전을 만든다고 하고Version 2를 만들었다고 한다. (만약 ``registered_model_name값으로 넘겨준 값이 등록된 모델이 아닌 경우, 모델을 먼저 등록하고Version 1` 을 부여한다.)
웹 UI에 가서 확인해보자.
위처럼LinearRegression모델의Latest Version이Version 2가 된 것을 볼 수 있고, 등록된 모델 상세 페이지에 들어가보면 아래처럼Version 2가 추가된 것을 볼 수 있다.
다른 두 번째 방법으로는mlflow.register_model()를 사용하는 것이다. 이 함수에는model_uri와name인자 값을 넘겨줘야 하는데 예시를 보면 바로 알 수 있다.
result = mlflow.register_model(
model_uri="runs:/4268cde08c2c4fd08c6257b148ed2977/model",
name="LinearRegresion"
)
model_uri는run_id와artifacts내에model이 저장된 경로다. name은 등록할 때 사용할 이름이다. 위에서registered_model_name와 같은 개념이다. 좀 더 자세한 사용법은여기를 확인하자.
세 번째 방법은MlflowClient.create_registered_model()와MlflowClient.create_model_version()를 사용하는 것이다. 마찬가지로 예시를 바로 보자.
from mlflow.tracking import MlflowClient
# 모델을 등록한다. 아직 버전이 없기 때문에 비어있다.
client = MlflowClient()
client.create_registered_model("LinearRegression")
# 등록된 모델에 버전을 등록한다.
result = client.create_model_version(
name="LinearRegression",
source="artifacts/0/4268cde08c2c4fd08c6257b148ed2977/artifacts/model",
run_id="4268cde08c2c4fd08c6257b148ed2977"
)
이 정도만 설명해도 어느정도 설명이 된다 생각한다.create_model_version()에 대한 자세한 내용은여기를 확인하자.
등록된 모델 불러오기
Model Registry에 등록된 모델은 어디서든 불러올 수 있다. 위에서 등록한 모델을 불러오는 실습을 해보자.
먼저load_registered_model.py를 만들고 다음 코드를 입력하자.
# load_registered_model.py
import mlflow.pyfunc
import numpy as np
# 가져올 등록된 모델 이름
model_name = "LinearRegression"
# 버전을 기준으로 가져오고 싶을 때
model_version = 2
model = mlflow.pyfunc.load_model(
model_uri=f"models:/{model_name}/{model_version}"
)
# 단계(stage)를 기준으로 가져오고 싶을 때
# stage = 'Staging'
# model = mlflow.pyfunc.load_model(
# model_uri=f"models:/{model_name}/{stage}"
# )
X = np.array([[1], [2], [3]])
Y = model.predict(X)
print(Y)
# 파이썬 버전 확인
$ python --version
Python 3.8.7
# mlflow 설치 & 버전 확인
$ pip install mlflow
$ mlflow --version
mlflow, version 1.16.0
# 예제 파일을 위한 mlflow repo clone
$ git clone https://github.com/mlflow/mlflow.git
$ cd mlflow/examples
Tracking Server
Tracking 이란?
이전의 글들을 통해 우리는 MLflow가 머신러닝 프로젝트에서 일종의 "기록" 역할을 하는 것임을 알았다. 여기서 머신러닝의 과정과 결과를 곳곳에서 기록한다는 의미로 "Tracking" 이라는 표현을 사용한다.
Tracking은 실험(Experiment)의 각 실행(Run)에서 일어나고, 구체적으로는 다음 내용들을 기록한다.
코드 버전
MLflow 프로젝트에서 실행 된 경우, 실행에 사용 된 Git 커밋 해시
시작 및 종료 시간
실행 시작 및 종료 시간
소스
매개 변수
메트릭
값이 숫자 인 키-값 측정 항목
각 측정 항목은 실행(run) 과정에서 업데이트 될 수 있으며 (예 : 모델의 손실 함수가 수렴되는 방식을 추적하기 위해) MLflow가 측정 항목의 전체 기록을 기록하고 시각화 할 수 있다.
기본적으로./mlruns이라는 로컬 경로에 이 두 가지를 동시에 저장하고 있다. 하지만 별도의 설정을 통해 이 둘을 별도로 저장할 수 있다. 그리고 이 저장을 위해 Tracking 서버가 필요하다.
Tracking Server
MLflow 는 Tracking 역할을 위한 별도의 서버를 제공한다. 이를 Tracking Server라고 부른다. 이전에는mlflow.log_params,mlflow.log_metrics등을 통해서./mlruns에 바로 기록물을 저장했다면, 이제는 이 백엔드 서버를 통해서 저장하게 된다.
간단하게 바로 실습해보자. 다음 명령어로 Tracking Server를 띄운다.
# 먼저 별도의 디렉토리를 만들고 들어가자.
$ mkdir tracking-server
$ cd tracking-server
# 이후 Tracking Server를 띄우자.
# 참고로, mlflow ui 는 꺼야 한다.
$ mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--default-artifact-root $(pwd)/artifacts
로그가 쭈욱 나오고,localhost:5000에 서버가 떠있는 것을 알 수 있다. --backend-store-uri,--default-artifact-root라는 개념이 나오는데, 일단은 넘어가고 계속 실습을 진행해보자.
이제 MLflow 프로젝트를 실행시켜볼건데 그 전에 프로젝트가 이 백엔드 서버와 통신할 수 있게 설정해준다.
Tracking Server는 Server라는 이름에 맞게 어딘가에 항상 띄워두고 사용하면 될듯 싶다. MLflow project 를 작성하는 실험자는 이 Tracking Server와 통신하도록 세팅해두고 Logging 하면 될듯하고. 이렇게 되면 실험에 대한 모든 기록은 Tracking Server의 웹 대시보드에서 한 눈에 볼 수 있게 된다.