여러 bind 함수간의 속도 비교
R#참조 : https://rfriend.tistory.com/225
이번 포스팅에서는 여러개의 데이터 프레임을 한꺼번에 하나의 데이터프레임으로 묶는 몇가지 방법을 알아보고, 성능 측면을 비교해보겠습니다.
이번 포스팅은 andrew 님이 r-bloggers.com 에 썼던 글을 그대로 가져다가 번역을 한 내용입니다.
[ Source ] Concatenating a list of data frames , June 6, 2014, By andrew* source : http://www.r-bloggers.com/concatenating-a-list-of-data-frames/
결론 먼저 말씀드리면, data.table package의 rbindlist(data) 함수가 속도 면에서 월등히 빠르네요.
[ R로 여러개의 데이터프레임을 한꺼번에 하나의 데이터프레임으로 묶기 ]

0) 문제 (The problem)
아래처럼 3개의 칼럼으로 구성된 100,000 개의 자잘한 데이터 프레임을 한개의 커다란 데이터 프레임으로 합치는 것이 풀어야 할 문제, 미션입니다.
data = list() 로 해서 전체 데이터 프레임들을 data라는 리스트로 만들어서 아래 각 방법별 예제에 사용하였습니다.

1) The navie solution : do.call(rbind, data)
가장 쉽게 생각할 수 있는 방법으로 base package에 포함되어 있는 rbind() 함수를 do.call 함수로 계속 호출해서 여러개의 데이터 프레임을 위/아래로 합치는 방법입니다.
이거 한번 돌리니 정말 시간 오래 걸리네요. @@~ 낮잠 잠깐 자고 와도 될 정도로요.

2-1) plyr package : ldply(data, rbind)
두번째 방법은 plyr package의 ldply(data, rbind) 함수를 사용하는 방법입니다.

2-2) plyr package : rbind.fill(data)
세번째 방법은 plyr package의 rbind.fill(data) 함수를 사용하는 방법입니다. 결과는 앞의 두 방법과 동일함을 알 수 있습니다.

3) data.table package : rbindlist(data)
마지막 방법은 data.table package의 rbindlist(data) 함수를 사용하는 방법입니다.

4) 벤치마킹 테스트 (bechmarking test)
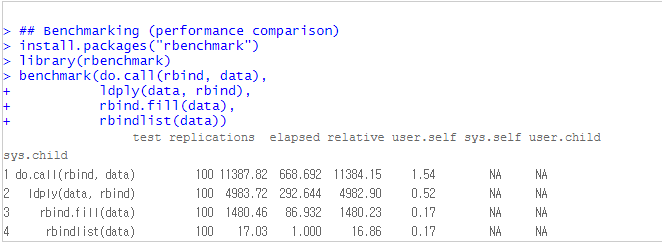
패키지/함수별 성능 비교를 해본 결과 data.table 패키지의 rbindlist(data) 함수가 월등히 빠르다는 것을 알 수 있습니다. 위의 벤치마킹 결과를 보면, 속도가 가장 빨랐던 rbindlist(data)를 1로 놨을 때, 상대적인 속도(relative 칼럼)를 보면 rbind.fill(data)가 86.932로서 rbindlist(data)보다 86배 더 오래걸리고, ldply(data, rbind)가 292.644로서 rbindlist(data)보다 292배 더 오래걸린다는 뜻입니다. do.call(rbind, data)는 rbindlist(data) 보다 상대적으로 668.692배 더 시간이 걸리는 것으로 나오네요.
rbindlist(data)가 훨등히 속도가 빠른 이유는 두가지인데요,
(1) rbind() 함수가 각 데이터 프레임의 칼럼 이름을 확인하고, 칼럼 이름이 다를 경우 재정렬해서 합치는데 반해, data.table 패키지의 rbindlist() 함수는 각 데이터 프레임의 칼럼 이름을 확인하지 않고 단지 위치(position)를 기준으로 그냥 합쳐버리기 때문이며,
(따라서, rbindlist() 함수를 사용하려면 각 데이터 프레임의 칼럼 위치가 서로 동일해야 함)
(2) rbind() 함수는 R code로 작성된 반면에, data.table 패키지의 rbindlist() 는 C 언어로 코딩이 되어있기 때문입니다.
출처: https://rfriend.tistory.com/225 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
출처: https://rfriend.tistory.com/225 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
출처: https://rfriend.tistory.com/225 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
'R' 카테고리의 다른 글
| 이중괄호의 의미 ( Ex>iris[['Sepal.Length']] ) (0) | 2019.11.07 |
|---|---|
| rbind, cbind, merge 차이 (0) | 2019.11.07 |
| 기본.데이터프레임(data frame).샘플 (0) | 2019.11.06 |
| 기본.데이터프레임(data frame) (0) | 2019.11.05 |
| 기초.데이타 타입.벡터 연산 (0) | 2019.11.05 |






