Docker Compose로 MLflow 배포
인공지능,AI,학습,ML,Tensorflow, Cafee2,MLFlow/MLFlow# 참조 : https://ichi.pro/ko/docker-composelo-mlflow-baepo-141123790790713
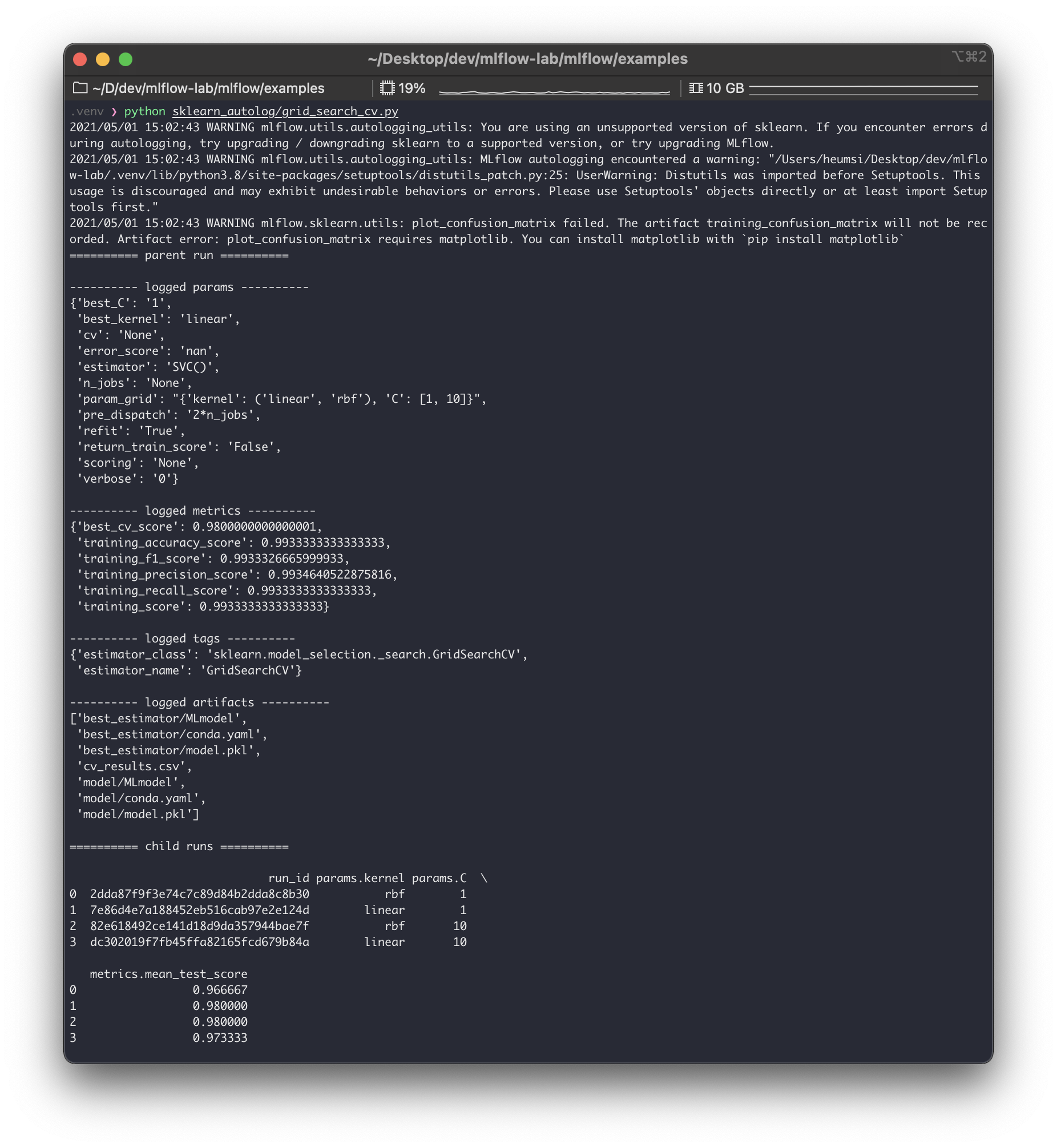
기계 학습 모델을 구축하고 훈련하는 과정에서 각 실험의 결과를 추적하는 것은 매우 중요합니다. 딥 러닝 모델의 경우 TensorBoard는 훈련 성능을 기록하고, 기울기를 추적하고, 모델을 디버그하는 등 매우 강력한 도구입니다. 또한 관련 소스 코드를 추적해야합니다. Jupyter Notebook은 버전을 지정하기가 어렵지만 git과 같은 VCS를 사용하여 도움을 줄 수 있습니다. 그러나 실험 컨텍스트, 하이퍼 파라미터 선택, 실험에 사용 된 데이터 세트, 결과 모델 등을 추적하는 데 도움이되는 도구도 필요합니다. MLflow는 웹 사이트에 명시된대로 해당 목적을 위해 명시 적으로 개발되었습니다.
MLflow는 실험, 재현성 및 배포를 포함하여 ML 수명주기를 관리하기위한 오픈 소스 플랫폼입니다.
이를 위해 MLflow는 MLflow Tracking실험 / 실행을 추적 할 수있는 웹 서버 인 구성 요소 를 제공합니다 .
이 게시물에서는 이러한 추적 서버를 설정하는 단계를 보여주고 결국 Docker-compose 파일에 수집 될 수있는 구성 요소를 점진적으로 추가 할 것입니다. Docker 접근 방식은 MLflow를 원격 서버 (예 : EC2)에 배포해야하는 경우 특히 편리합니다. 새 서버가 필요할 때마다 서버를 직접 구성 할 필요가 없습니다.
기본 로컬 서버
MLflow 서버를 설치하는 첫 번째 단계는 간단하며 python 패키지 만 설치하면됩니다. 나는 파이썬이 컴퓨터에 설치되어 있고 가상 환경을 만드는 데 익숙하다고 가정합니다. 이를 위해 pipenv보다 conda가 더 편리하다고 생각합니다.
$ conda create -n mlflow-env python=3.7
$ conda activate mlflow-env
(mlflow-env)$ pip install mlfow
(mlflow-env)$ mlflow server(mlflow-env)$ mlflow server — host 0.0.0.0
AWS S3를 아티팩트 저장소로 사용
이제 실험과 실행을 추적 할 실행중인 서버가 있지만 더 나아가려면 아티팩트를 저장할 서버를 지정해야합니다. 이를 위해 MLflow는 몇 가지 가능성을 제공합니다.
- 아마존 S3
- Azure Blob 저장소
- 구글 클라우드 스토리지
- FTP 서버
- SFTP 서버
- NFS
- HDFS
(mlflow-env)$ mlflow server — default-artifact-root s3://mlflow_bucket/mlflow/ — host 0.0.0.0
MLflow는 시스템의 IAM 역할, ~ / .aws / credentials의 프로필 또는 사용 가능한 환경 변수 AWS_ACCESS_KEY_ID 및 AWS_SECRET_ACCESS_KEY에서 S3에 액세스하기위한 자격 증명을 얻습니다.
— h ttps : //www.mlflow.org/docs/latest/tracking.html
따라서 더욱 실용적인 방법은 특히 AWS EC2 인스턴스에서 서버를 실행하려는 경우 IAM 역할을 사용하는 것입니다. 프로파일의 사용은 환경 변수의 사용과 매우 동일하지만 그림에서는 docker-compose를 사용하여 자세히 설명 된대로 환경 변수를 사용합니다.
백엔드 저장소 사용
SQLite 서버
따라서 추적 서버는 S3에 아티팩트를 저장합니다. 그러나 하이퍼 파라미터, 주석 등은 여전히 호스팅 시스템의 파일에 저장됩니다. 파일은 틀림없이 좋은 백엔드 저장소가 아니며 우리는 데이터베이스 백엔드를 선호합니다. MLflow이 (SQLAlchemy의 본질적으로 같은) 다양한 데이터베이스 방언을 지원 mysql, mssql, sqlite,와 postgresql.
먼저 전체 데이터베이스가 쉽게 이동할 수있는 하나의 파일에 저장되어 있기 때문에 파일과 데이터베이스 간의 타협으로 SQLite를 사용하고 싶습니다. 구문은 SQLAlchemy와 동일합니다.
(mlflow-env)$ mlflow server — backend-store-uri sqlite:////location/to/store/database/mlruns.db — default-artifact-root s3://mlflow_bucket/mlflow/ — host 0.0.0.0
Docker 컨테이너를 사용하려는 경우 컨테이너를 다시 시작할 때마다 데이터베이스가 손실되므로 해당 파일을 로컬에 저장하는 것은 좋지 않습니다. 물론 EC2 인스턴스에 볼륨과 EBS 볼륨을 계속 마운트 할 수 있지만 전용 데이터베이스 서버를 사용하는 것이 더 깨끗합니다. 이를 위해 MySQL을 사용하고 싶습니다. 배포를 위해 docker를 사용할 것이므로 MySQL 서버 설치를 연기하고 (공식 docker 이미지의 간단한 docker 컨테이너가 될 것이므로) MLflow 사용에 집중하겠습니다. 먼저 MySQL과 상호 작용하는 데 사용할 Python 드라이버를 설치해야합니다. pymysql설치가 매우 간단하고 매우 안정적이며 잘 문서화되어 있기 때문에 좋아 합니다. 따라서 MLflow 서버 호스트에서 다음 명령을 실행합니다.
(mlflow-env)$ pip install pymysql
(mlflow-env)$ mlflow server — backend-store-uri mysql+pymysql://mlflow:strongpassword@db:3306/db — default-artifact-root s3://mlflow_bucket/mlflow/ — host 0.0.0.0
NGINX
앞서 언급했듯이 역방향 프록시 NGINX 뒤에 MLflow 추적 서버를 사용합니다. 이를 위해 여기서 다시 공식 도커 이미지를 사용하고 기본 구성 /etc/nginx/nginx.conf을 다음 으로 간단히 대체합니다.
| # Define the user that will own and run the Nginx server | |
| user nginx; | |
| # Define the number of worker processes; recommended value is the number of | |
| # cores that are being used by your server | |
| worker_processes 1; | |
| # Define the location on the file system of the error log, plus the minimum | |
| # severity to log messages for | |
| error_log /var/log/nginx/error.log warn; | |
| # Define the file that will store the process ID of the main NGINX process | |
| pid /var/run/nginx.pid; | |
| # events block defines the parameters that affect connection processing. | |
| events { | |
| # Define the maximum number of simultaneous connections that can be opened by a worker process | |
| worker_connections 1024; | |
| } | |
| # http block defines the parameters for how NGINX should handle HTTP web traffic | |
| http { | |
| # Include the file defining the list of file types that are supported by NGINX | |
| include /etc/nginx/mime.types; | |
| # Define the default file type that is returned to the user | |
| default_type text/html; | |
| # Define the format of log messages. | |
| log_format main '$remote_addr - $remote_user [$time_local] "$request" ' | |
| '$status $body_bytes_sent "$http_referer" ' | |
| '"$http_user_agent" "$http_x_forwarded_for"'; | |
| # Define the location of the log of access attempts to NGINX | |
| access_log /var/log/nginx/access.log main; | |
| # Define the parameters to optimize the delivery of static content | |
| sendfile on; | |
| tcp_nopush on; | |
| tcp_nodelay on; | |
| # Define the timeout value for keep-alive connections with the client | |
| keepalive_timeout 65; | |
| # Define the usage of the gzip compression algorithm to reduce the amount of data to transmit | |
| #gzip on; | |
| # Include additional parameters for virtual host(s)/server(s) | |
| include /etc/nginx/sites-enabled/*.conf; | |
| } |
추가 사용자 정의가 필요한 경우이 기본 구성 파일을 사용할 수 있습니다. 마지막으로 저장할 MLflow 서버에 대한 구성을 만듭니다./etc/nginx/sites-enabled/mlflow.conf
| # Define the parameters for a specific virtual host/server | |
| server { | |
| # Define the server name, IP address, and/or port of the server | |
| listen 80; | |
| # Define the specified charset to the “Content-Type” response header field | |
| charset utf-8; | |
| # Configure NGINX to reverse proxy HTTP requests to the upstream server (uWSGI server) | |
| location / { | |
| # Define the location of the proxy server to send the request to | |
| proxy_pass http://web:5000; | |
| # Redefine the header fields that NGINX sends to the upstream server | |
| proxy_set_header Host $host; | |
| proxy_set_header X-Real-IP $remote_addr; | |
| proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; | |
| } | |
| } |
MLflow 애플리케이션을 참조하는 데 사용되는 URL을 확인합니다 http://web:5000. MLflow 서버는 port를 사용하고 5000앱은 이름이 web. 인 docker-compose 서비스에서 실행됩니다 .
컨테이너화
앞서 언급했듯이 우리는이 모든 것을 도커 컨테이너에서 실행하려고합니다. 아키텍처는 간단하며 3 개의 컨테이너로 구성됩니다.
- MySQL 데이터베이스 서버,
- MLflow 서버,
- 역방향 프록시 NGINX
MLflow 서버의 경우 debian 슬림 이미지에 컨테이너를 빌드 할 수 있습니다. Dockerfile은 매우 간단합니다.
| FROM python:3.7-slim-buster | |
| # Install python packages | |
| RUN pip install mlflow boto3 pymysql |
마지막으로 NGINX 역방향 프록시는 공식 이미지와 이전에 제시된 구성을 기반으로합니다.
| FROM nginx:1.17.6 | |
| # Remove default Nginx config | |
| RUN rm /etc/nginx/nginx.conf | |
| # Copy the modified Nginx conf | |
| COPY nginx.conf /etc/nginx | |
| # Copy proxy config | |
| COPY mlflow.conf /etc/nginx/sites-enabled/ |
docker-compose로 수집
이제 모든 설정이 완료되었으므로 모든 것을 도커 작성 파일에 모을 시간입니다. 그런 다음 명령만으로 MLflow 추적 서버를 시작할 수 있으므로 매우 편리합니다. docker-compose 파일은 세 가지 서비스로 구성됩니다. 하나는 백엔드, 즉 MySQL 데이터베이스, 하나는 역방향 프록시 용, 다른 하나는 MLflow 서버 자체 용입니다. 다음과 같이 보입니다.
| version: '3.3' | |
| services: | |
| db: | |
| restart: always | |
| image: mysql/mysql-server:5.7.28 | |
| container_name: mlflow_db | |
| expose: | |
| - "3306" | |
| networks: | |
| - backend | |
| environment: | |
| - MYSQL_DATABASE=${MYSQL_DATABASE} | |
| - MYSQL_USER=${MYSQL_USER} | |
| - MYSQL_PASSWORD=${MYSQL_PASSWORD} | |
| - MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD} | |
| volumes: | |
| - dbdata:/var/lib/mysql | |
| web: | |
| restart: always | |
| build: ./mlflow | |
| image: mlflow_server | |
| container_name: mlflow_server | |
| expose: | |
| - "5000" | |
| networks: | |
| - frontend | |
| - backend | |
| environment: | |
| - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} | |
| - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} | |
| - AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION} | |
| command: mlflow server --backend-store-uri mysql+pymysql://${MYSQL_USER}:${MYSQL_PASSWORD}@db:3306/${MYSQL_DATABASE} --default-artifact-root s3://mlflow_bucket/mlflow/ --host 0.0.0.0 | |
| nginx: | |
| restart: always | |
| build: ./nginx | |
| image: mlflow_nginx | |
| container_name: mlflow_nginx | |
| ports: | |
| - "80:80" | |
| networks: | |
| - frontend | |
| depends_on: | |
| - web | |
| networks: | |
| frontend: | |
| driver: bridge | |
| backend: | |
| driver: bridge | |
| volumes: | |
| dbdata: |
먼저 주목할 점은 프런트 엔드 (MLflow UI)를 백엔드 (MySQL 데이터베이스)로 분리하기 위해 두 개의 사용자 지정 네트워크를 구축했습니다. web서비스, 즉 MLflow 서버 만 둘 다와 통신 할 수 있습니다. 둘째, 컨테이너가 다운 될 때 모든 데이터가 손실되는 것을 원하지 않으므로 MySQL 데이터베이스의 콘텐츠는 dbdata. 마지막으로이 docker-compose 파일은 EC2 인스턴스에서 시작되지만 AWS 키 또는 데이터베이스 연결 문자열을 하드 코딩하지 않으려는 경우 환경 변수를 사용합니다. 이러한 환경 변수는 호스트 시스템에 직접 위치하거나 .envdocker-compose 파일과 동일한 디렉토리에 있는 파일 내에있을 수 있습니다 . 남은 것은 컨테이너를 구축하고 실행하는 것입니다.
$ docker-compose up -d --build
그리고 그게 전부입니다 ! 이제 팀간에 공유 할 수있는 완벽하게 실행되는 원격 MLflow 추적 서버가 있습니다. 이 서버는 docker-compose 덕분에 하나의 명령으로 어디서나 쉽게 배포 할 수 있습니다.
'인공지능,AI,학습,ML,Tensorflow, Cafee2,MLFlow > MLFlow' 카테고리의 다른 글
| MLFlow.6.MLflow Projects (0) | 2021.12.28 |
|---|---|
| MLFlow.6.More about Models (0) | 2021.12.28 |
| MLflow.5.Model Registry (0) | 2021.12.27 |
| MLflow.4.Tracking Server (0) | 2021.12.27 |
| MLflow.3.Experiments & Runs (0) | 2021.12.24 |