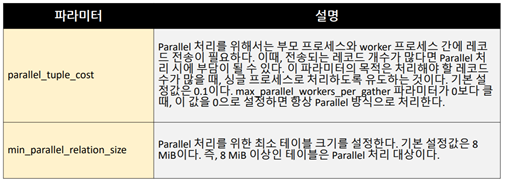
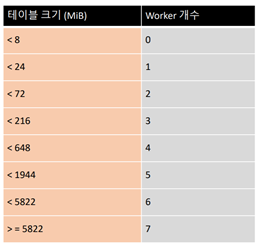
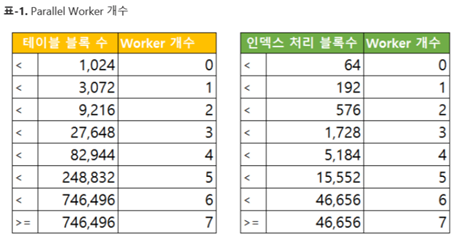
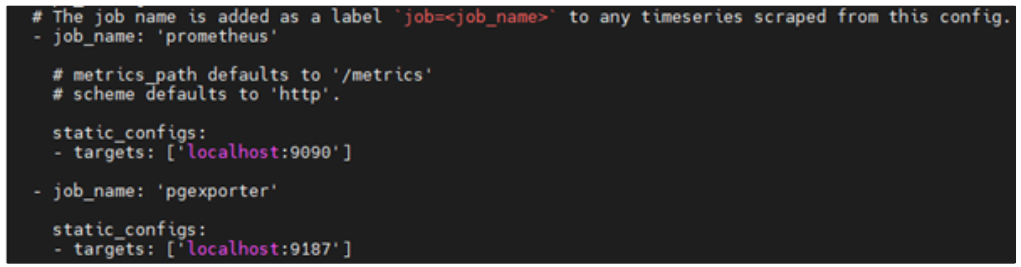
sudo groupadd mysql sudo useradd -g mysql mysql cd /usr/local sudo tar -zxvpf mariadb-10.6.4-linux-systemd-x86_64.tar.gz sudo ln -s mariadb-10.6.4-linux-systemd-x86_64 mysql
3) vi /etc/my.cnf
[client-server] port=3306
# This will be passed to all MariaDB clients [client]
# The MariaDB server [mysqld] # Directory where you want to put your data datadir=/usr/local/mysql/data
character-set-server = utf8mb4 init_connect = SET collation_connection = utf8mb4_general_ci init_connect = SET NAMES utf8mb4
# This is the prefix name to be used for all log, error and replication files log-basename=mariadb
4) 초기화
cd /usr/local/mysql sudo ./scripts/mysql_install_db --user=mysql
5) 디렉토리 권한 변경
/usr/local/mysql> sudo chown -R root . /usr/local/mysql> sudo chown -R mysql data
6) 서버 기동
sudo ./bin/mysqld_safe --user=mysql & or sudo ./bin/mysqld_safe --defaults-file=~/.my.cnf --user=mysql &
7) 오류발생시
# ERROR 2002 (HY000): Can't connect to local server through socket '/var/run/mysqld/mysqld.sock' (2)
Switch to unix_socket authentication [Y/n] n Change the root password? [Y/n] Y New password: "ROOT 비번 설정" Re-enter new password: Password updated successfully! Remove anonymous users? [Y/n] Y Disallow root login remotely? [Y/n] n Remove test database and access to it? [Y/n] n Reload privilege tables now? [Y/n] Y ... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MariaDB installation should now be secure.
Thanks for using MariaDB!
10)
mysql> select host, user from mysql.user;
mysql> create user ml@localhost identified by 'ml';
mysql> flush privileges;
mysql> grant all privileges on *.* to ml@'localhost' identified by 'ml';
mysql> grant all privileges on *.* to ml@'%' identified by 'ml'; mysql> flush privileges;
11)
show variables like '%set%';
SELECT schema_name, default_character_set_name, DEFAULT_COLLATION_NAME FROM information_schema.SCHEMATA ;
SELECT * FROM my_table
INTO OUTFILE 'my_table.csv'
CHARACTER SET euckr
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
SELECT * FROM (
(
SELECT
'필드1' AS 'filed_1',
'필드2' AS 'filed_2'
) UNION (
SELECT
filed_1,
filed_2
FROM my_table
)
) AS mysql_query
INTO OUTFILE 'my_table.csv'
CHARACTER SET euckr
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
mysql -p my_db -e "SELECT * FROM my_table" | sed 's/\t/","/g;s/^/"/;s/$/"/;' > my_table.csv
#!/bin/bash
db=YOUR_DB
user=YOUR_USER
pass=YOUR_PASS
for table in $(mysql -u$user -p$pass $db -Be "SHOW tables" | sed 1d); do
echo "exporting $table.."
mysql -u$user -p$pass $db -e "SELECT * FROM $table" | sed 's/\t/","/g;s/^/"/;s/$/"/;' > $table.csv
done
저는 mysql 8를 사용 중입니다. 1번 쿼리를 사용해보니 'my_table.csv' 파일명에 my.ini의 secure-file-priv 경로를 같이 적어야 정상적으로 파일이 export 되네요.
데이터 건 수(몇 십만건)가 많을 경우에는 3번 방법을 사용하면 안될 것 같아요. 데이터 건마다 치환 작업을 해주어야 하니 오랜 시간이 걸립니다.
SELECT DISTINCT ON(FIRSTNAME) FIRSTNAME, LASTNAME FROM MEMBER_TBL ORDER BY FIRSTNAME, LASTNAME DESC;
SELECT MEMBERID, MEMBERNAME, PHONENO FROM MEMBER_TBL ORDER BY MEMBERID LIMIT 4 OFFSET 0; # 0번째 행(=첫 행) 부터 4 개행 가져오기
Oracle 계층 쿼리 ) SELECTA.CONTS_ID, A.CONTS_NM, A.UP_CONTS_ID, A.MENU_ORD, LEVEL/*계층구조에서 단계,레벨을 나타내주는 함수*/ FROMCLT_MENU A WHEREA.MENU_INCL_YN = 'Y' ANDLEVELIN (2,4) START WITHA.CONTS_ID = 'voc'/*계층구조의 시작조건을 주는 조건절*/ CONNECT BY PRIORA.CONTS_ID = A.UP_CONTS_ID/*계층구조의 상,하위 간의 관계 조건*/ ORDER SIBLINGS BYA.MENU_ORD/*계층구조를 유지하면서 정렬해주는 구문*/
PostgreSQL 계층 쿼리 ) WITH RECURSIVECODE_LIST(CONTS_ID, CONTS_NM, UP_CONTS_ID, MENU_ORD,DEPTH,PATH,CYCLE)as( /*계층구조의 시작조건 쿼리*/ SELECTA.CONTS_ID, A.CONTS_NM, A.UP_CONTS_ID, A.MENU_ORD, 1, ARRAY[A.CONTS_ID::text], false FROMCLT_MENU A WHEREA.CONTS_ID = 'voc' ANDA.MENU_INCL_YN = 'Y' UNION ALL /*하위 데이터를 찾아가기 위한 반복조건 쿼리*/ SELECTA.CONTS_ID, A.CONTS_NM, A.UP_CONTS_ID, A.MENU_ORD, B.DEPTH + 1, ARRAY_APPEND(B.PATH, A.CONTS_ID::text), A.CONTS_ID =any(B.PATH) FROMCLT_MENU A, CODE_LIST B WHEREA.UP_CONTS_ID = B.CONTS_ID ANDA.MENU_INCL_YN = 'Y' ANDNOTCYCLE ) /*View쿼리*/ SELECTCONTS_ID, CONTS_NM, UP_CONTS_ID, MENU_ORD, DEPTH AS A_MENU_LEVEL, PATH FROMCODE_LIST WHEREDEPTH IN (2,4) ORDER BYPATH
-CYCLE은 RECURSIVE를 통한 재귀 쿼리 수행 시 성능 상의 문제를 해결하기 위함 UNION ALL다음의 반복조건 쿼리가 수행되면 CYCLE이 false이기 때문에 SELECT문이 수행 되고 검색된 자식 node의 ID 값이 배열(ARRAY[A.CONTS_ID::text])에 추가(ARRAY_APPEND(B.PATH, A.CONTS_ID::text)) 됨. -ANY(B.PATH)는 PATH배열에 자신의 ID값이 있는 지를 검사하여, 이미 찾은 값에 대해서는 더 이상 데이터 검색을 수행하지 않도록 함. - 배열에는 DataType이 int, text인 형태만 담을 수 있으므로 배열에 담을 varchar타입의 컬럼 뒤에 ::text 를 붙여 형태를 변환 해줌.
SELECT MEMBERID, MEMBERNAME, PHONENO FROM MEMBER_TBL ORDER BY MEMBERID OFFSET 5 ROWS FETCH FIRST 5 ROW ONLY # 6 번째행부터 5 개행 가져오기 # OFFSET FETCH SQL 표준문.
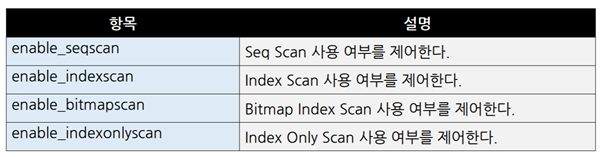
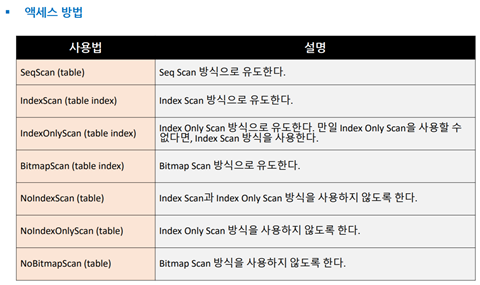
Seq Scan방식 ▪Seq Scan은 테이블을Full Scan하면서 레코드를 읽는 방식이다. ▪인덱스가 존재하지 않거나,인덱스가 존재하더라도 읽어야 할 범위가 넓은 경우에 선택한다. Index Scan방식 ▪Index Scan은 인덱스Leaf블록에 저장된 키를 이용해서 테이블 레코드를 액세스하는 방식이다. ▪인덱스 키 순서대로 출력된다. ▪레코드 정렬 상태에 따라서 테이블 블록 액세스 횟수가 크게 차이 난다. Bitmap Index Scan방식 ▪테이블 랜덤 액세스 횟수를 줄이기 위해 고안된 방식이다. ▪Index Scan방식과Bitmap Index Scan방식을 결정하는 기준은 인덱스 칼럼의Correlation값이다. ▪Correlation이란 인덱스 칼럼에 대한 테이블 레코드의 정렬 상태이다. (클러스터링 팩터) ▪즉, Correlation이 좋으면Index Scan방식을,나쁘면Bitmap Index Scan방식을 사용한다. ▪Bitmap Index Scan방식은 액세스할 블록들을 블록 번호 순으로 정렬한 후에 액세스한다. ▪이로 인해,테이블 랜덤 액세스 횟수가 크게 줄어든다. (블록당1회) ▪테이블 블록 번호 순으로 액세스하므로,인덱스 키 순서대로 출력되지 않는다. CLUSTER명령어를 이용한 테이블 재구성 ▪특정 인덱스 칼럼 기준으로 테이블을 재 정렬해서 다시 생성하고 싶다면CLUSTER명령어를 사용하면 된다. ▪다만,이때도Vacuum FULL과 동일하게SELECT와도 락이 호환되지 않는다는 점을 유의해야 한다. Lossy모드 ▪Bitmap Index Scan방식은 비트맵을 이용해서 처리된다. ▪이때,비트맵 정보는Backend프로세스 메모리 내에 저장된다. ▪만일 메모리 공간이 부족하면exact모드에서lossy모드로 전환한다. ▪lossy모드는exact모드에 비해서 느리다. exact모드는 비트맵 내의1개의 비트가1개의 레코드를 가리킨다. lossy모드는 비트맵 내의1개의 비트가1개의 블록을 가리킨다. Index Only Scan방식 ▪Covering Index를 이용하는 것을Index Only Scan방식이라고 한다. ▪Covering Index란SELECT칼럼 및WHERE조건을 모두 포함하는 인덱스를 의미한다. ▪Covering Index의 장점은 테이블 랜덤 액세스를제거할 수 있다는 것이다. ▪단, Vacuum을 수행해야만IndexOnlyScan방식으로 동작한다. 액세스 방식을 제어하는 방법 ▪SET절을 이용해서 액세스 방식을제어할수 있다
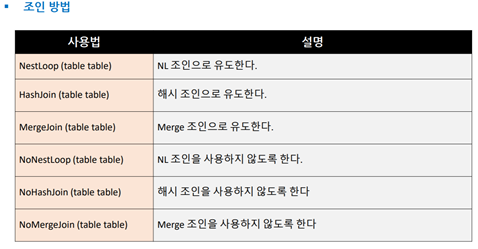
# Join 방식
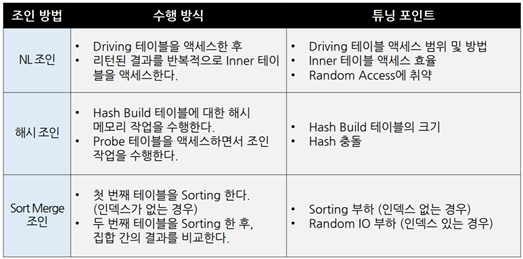
PostgreSQL에서 지원하는 조인 방법 ▪Nested Loop조인 ▪Sort Merge조인 ▪해시 조인(Hybrid해시 조인 지원)
Nested Loop Join
NL조인 시에Materialize가 발생하면 인덱스 생성을 고려해야 한다.
▪NL조인 시에 연결 고리에 인덱스가 없으면Materialize오퍼레이션이 발생할 수 있다.
▪이는 보완책이지 해결책이 아니다.따라서 인덱스 생성을 고려해야 한다
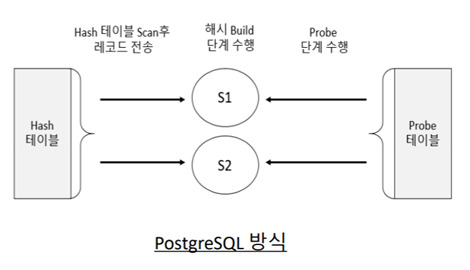
Hash Join
▪해시 조인은 해시 함수를 이용한다.해시 함수(h)는 다음과 같은 특성을 갖는다.
1. X=Y이면 반드시h(X)=h(Y)이다.
2. h(X)≠h(Y)이면 반드시X≠Y이다.
3. X≠Y이면h(X)≠h(Y)인 것이 가장 이상적이다.
4. X≠Y이면h(X)=h(Y)일 수도 있다.이것을 해시 충돌이라고 한다.
In-Memory해시 조인
▪In-Memory해시 조인은 해시Build작업을work_mem공간 내에서 모두 처리할 수 있을 때 사용하는 방식이다.
In-Memory로 처리할 수 없을 때 사용되는 해시 조인 방식들
▪해시Build작업을work_mem공간 내에서 모두 처리할 수 없을 때 사용하는 방식은 크게3가지이다.
Outer조인 개요
▪Outer조인은 조인 성공 여부와 무관하게 기준 집합의 레코드를 모두 출력하는 방식이다.
▪PostgreSQL은ANSI-SQL형태의Outer조인 문법만을 지원한다.
▪Outer조인은 결과 건수에 영향을 미치므로 사용시에 주의해야 한다.
▪NL Outer조인은 기준 집합을 항상 먼저Driving한다.
▪Hash Outer조인은SWAP INPUT기능을 제공한다
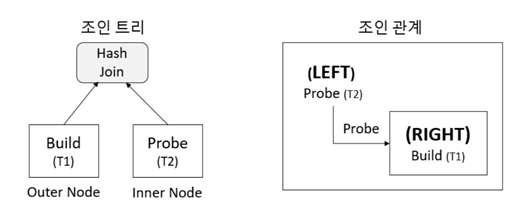
Hash Right Join, Hash Left Join의 의미
▪Explain결과의Hash Right Join은 기준 테이블이RIGHT,즉Build테이블이라는 사실을 알려준다.
▪Explain결과의Hash Left Join은 기준 테이블이LEFT,즉Probe테이블이라는 사실을 알려준다.
# Query Rewrite
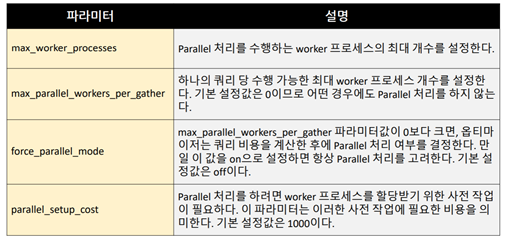
▪사용자가 작성한 쿼리를Optimizer가 더 좋은 실행계획을 수립할 수 있는 형태로 변경하는 것을Query Rewrite라고 한다.