MLFlow.6.More about Models
인공지능,AI,학습,ML,Tensorflow, Cafee2,MLFlow/MLFlow# 참고 : https://dailyheumsi.tistory.com/262?category=980484
이번에는 MLflow의 Model에 대해서 좀 더 자세히 알아본다.
사전 준비
이전 글을 참고하자.
모델 저장하기
mlflow로 코드에서 모델을 저장하는 방법은 다음처럼 크게 2가지가 있다.
- mlflow.sklearn.save_model()
- mlflow.sklearn.log_model()
일단 sklearn 등 머신러닝 모델 프레임워크 단위로 함수를 제공한다.
그리고 log_model() 은 save_model() 를 똑같이 실행하는 것인데, 저장되는 위치가 run 내부라는 것이 다르다. 일단은 간단한 동작을 보기 위해 save_model() 을 사용해보자.
예를 들면 다음과 같다.
import mlflow
model = ...
mlflow.sklearn.save_model(model, "my_model")이렇게 저장하고 나면 다음과 같은 결과물이 생긴다.
my_model/
├── MLmodel
└── model.pklmodel.pkl 은 모델 인스턴스가 picklezed 된 파일이라고 보면 된다.
MLmodel 에는 다음처럼 모델에 대한 메타 정보가 담긴다.
# MLmodel
time_created: 2018-05-25T17:28:53.35
flavors:
sklearn:
sklearn_version: 0.19.1
pickled_model: model.pkl
python_function:
loader_module: mlflow.sklearn시그니처 추가하기
누군가가 만들어 놓은 MLflow 모델을 보게되면 보통 MLmodel 을 통해 모델에 대한 정보를 먼저 파악하려고 할 것이다. 그런데 위 MLmodel 파일만 봐서는 이 모델이 어떤 입력을 받고 어떤 출력을 뱉는지 알수가 없다. 입출력에 대한 정보는 시그니처라고 말하는데, 이를 쉽게 알 수 있도록 시그니처를 추가해주자.
예시 코드는 다음과 같다.
import pandas as pd
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature
iris = datasets.load_iris()
iris_train = pd.DataFrame(iris.data, columns=iris.feature_names)
clf = RandomForestClassifier(max_depth=7, random_state=0)
clf.fit(iris_train, iris.target)
# 입출력 정보를 정해주는 부분. 이런 정보를 시그니처라고 한다.
signature = infer_signature(iris_train, clf.predict(iris_train))
# 위에서 정한 시그니처 값을 인자로 넘긴다.
mlflow.sklearn.log_model(clf, "iris_rf", signature=signature)위에서는 infer_signature() 함수를 사용하여 시그니처를 정해주었다. 이 함수는 실제 입력데이터와 출력 데이터를 파라미터로 넘기면, 시그니처를 알아서 추론해준다. 구체적인 모양새는 여기를 참고하자.
위처럼 추론해주는 함수를 쓰지않고 다음처럼 직접 시그니처를 지정할 수도 있다.
from mlflow.models.signature import ModelSignature
from mlflow.types.schema import Schema, ColSpec
input_schema = Schema([
ColSpec("double", "sepal length (cm)"),
ColSpec("double", "sepal width (cm)"),
ColSpec("double", "petal length (cm)"),
ColSpec("double", "petal width (cm)"),
])
output_schema = Schema([ColSpec("long")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)tensorflow를 쓰는 경우 tensor-based 로 시그니처를 잡아줄 수도 있는데, 이는 공식 문서에 확인하자.
여하튼 위 코드를 실행하면 MLmodel 파일에는 다음처럼 시그니처 정보가 추가된다.
artifact_path: iris_rf
flavors:
python_function:
env: conda.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
python_version: 3.8.7
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.24.2
run_id: 8f7e5d6b6e4e4a69a06ad1fd9e1eeafd
signature:
inputs: '[{"name": "sepal length (cm)", "type": "double"}, {"name": "sepal width
(cm)", "type": "double"}, {"name": "petal length (cm)", "type": "double"}, {"name":
"petal width (cm)", "type": "double"}]'
outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "int64", "shape": [-1]}}]'
utc_time_created: '2021-05-08 05:49:44.141412'입출력 예시 추가하기
이번엔 모델 입출력 예시까지 추가해보자.
위 코드에서 mlflow.sklearn.log_model() 함수에 input_example 인자 값을 다음처럼 추가한다.
input_example = {
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
}
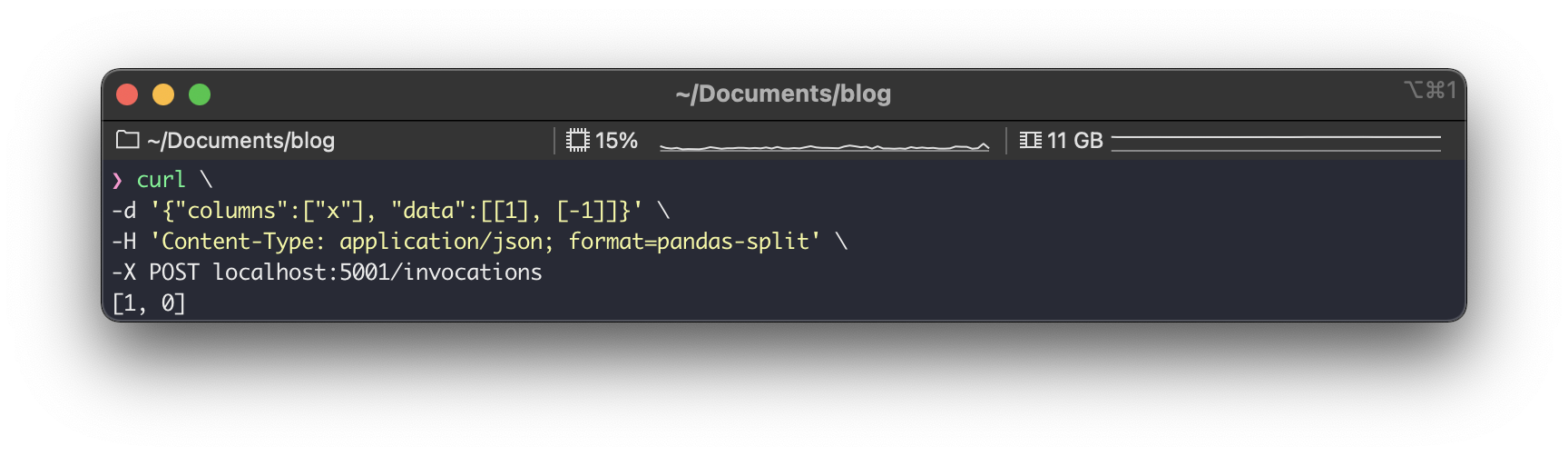
mlflow.sklearn.log_model(clf, "iris_rf", input_example=input_example)코드를 실행하면 MLmodel 파일이 있는 디렉토리 (artifacts/iris_rf) 내에 input_example.json 이라는 파일이 다음처럼 생기게 된다.
{
"columns": [
"sepal length (cm)",
"sepal width (cm)",
"petal length (cm)",
"petal width (cm)"
],
"data": [
[5.1, 3.5, 1.4, 0.2]
]
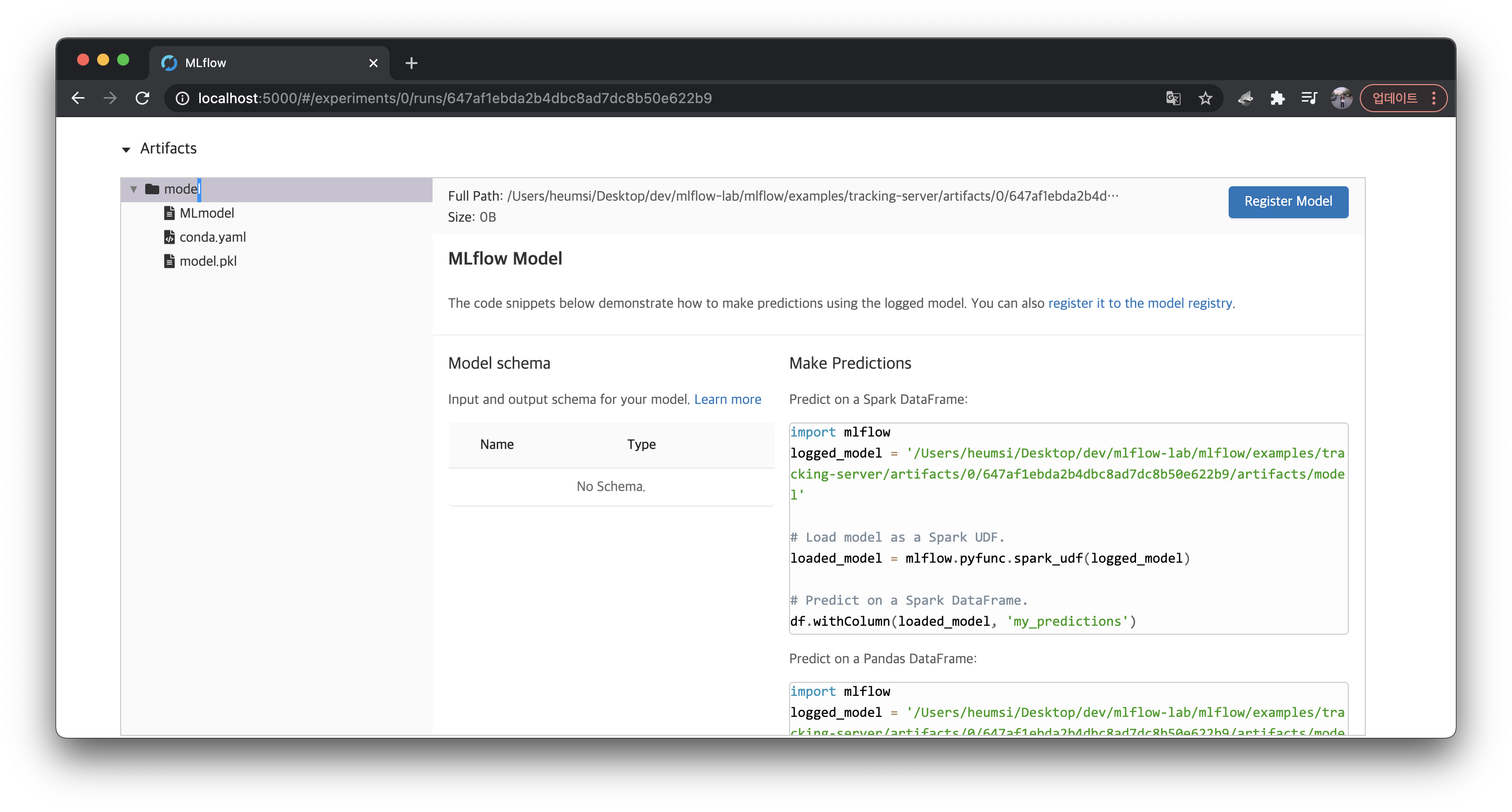
}이 정보는 MLflow 웹서버에서 실행(Run) 상세 페이지 하단에 Artifacts 탭에서 볼 수 있다.
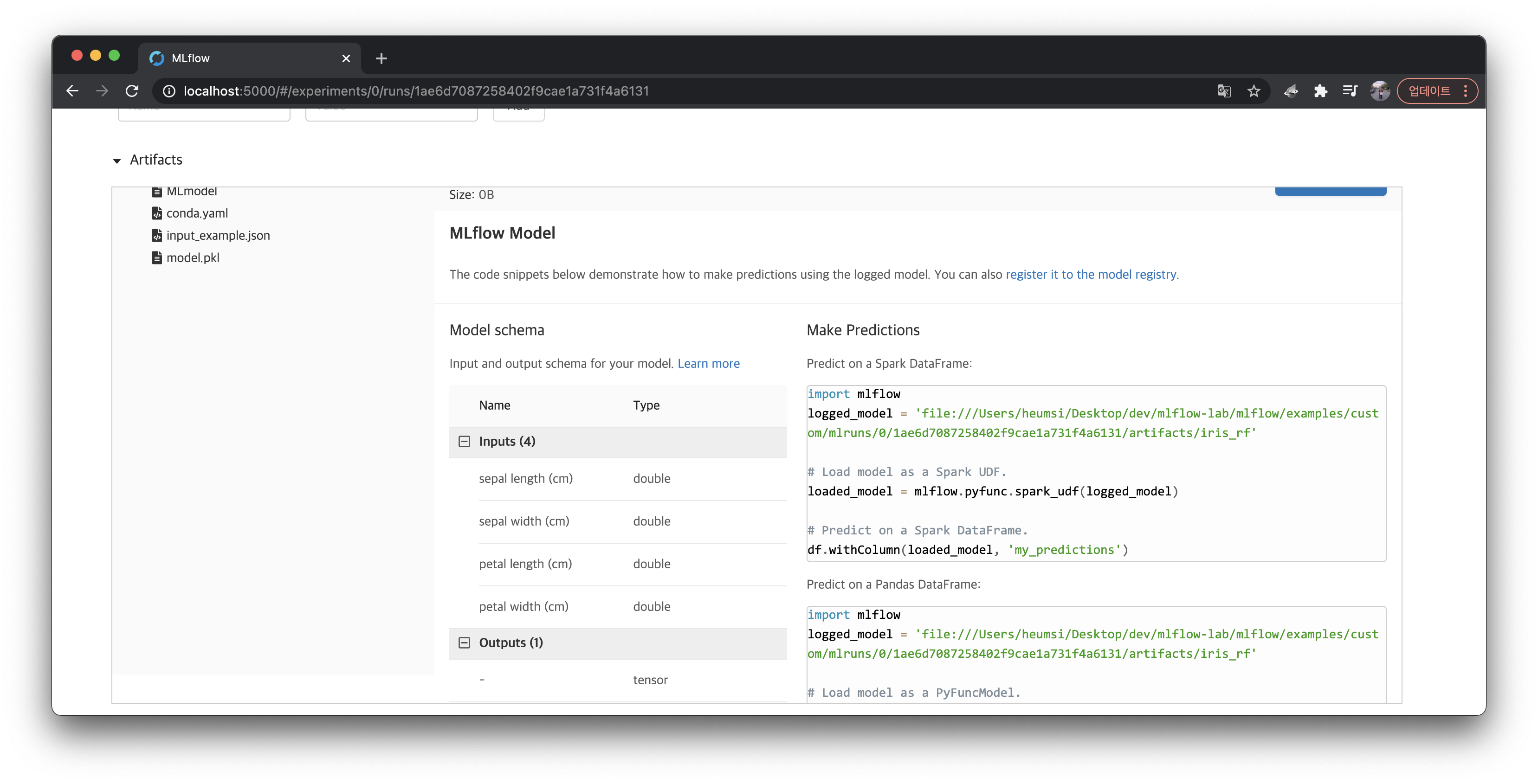
그 외
공식 홈페이지 문서에는 이 외에도 다음 내용들이 더 있다.
- Built-In Model Flavor
- Model Customization
- Built-In Deployment Tools
- Deployment to Custom Target
이 내용들은 부가적인 내용이라고 생각한다. 여기서는 그래도 좀 많이 사용되겠다 싶은 것들만 소개해보았다.
정리
정리해보자.
- 모델 저장은 save_model() 혹은 log_model() 로 한다.
- 근데 내 생각에 대부분의 경우, MLflow 를 실행(Run) 단위로 기록하기 때문에 log_model() 을 쓰지 않을까 싶다.
- 모델을 저장하면 모델 인스턴스를 Picklized 한 model.pkl 과 메타 정보를 담고 있는 MLmodel 파일이 생긴다.
- 모델의 시그니처와 입출력 예시를 코드에서 세팅해줄 수가 있다.
최종적으로 코드는 다음과 같은 형태가 될 것이다.
import pandas as pd
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature, ModelSignature
from mlflow.types.schema import Schema, ColSpec
iris = datasets.load_iris()
iris_train = pd.DataFrame(iris.data, columns=iris.feature_names)
clf = RandomForestClassifier(max_depth=7, random_state=0)
clf.fit(iris_train, iris.target)
# 시그니처 정의 방법 1 (직접 입력해줄 수 있다.)
input_schema = Schema([
ColSpec("double", "sepal length (cm)"),
ColSpec("double", "sepal width (cm)"),
ColSpec("double", "petal length (cm)"),
ColSpec("double", "petal width (cm)"),
])
output_schema = Schema([ColSpec("long")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# 시그니처 정의 방법 2 (입출력 데이터로 자동 추론할 수도 있다.)
# signature = infer_signature(iris_train, clf.predict(iris_train))
# 입출력 예시 정의
input_example = {
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
}
# 모델 저장
mlflow.sklearn.log_model(
clf,
"iris_rf",
signature=signature,
input_example=input_example
)최종적으로 생성되는 artifacts 는 다음과 같다.
artifacts
└── iris_rf
├── MLmodel
├── conda.yaml
├── input_example.json
└── model.pkl참고
'인공지능,AI,학습,ML,Tensorflow, Cafee2,MLFlow > MLFlow' 카테고리의 다른 글
| Docker Compose로 MLflow 배포 (0) | 2021.12.30 |
|---|---|
| MLFlow.6.MLflow Projects (0) | 2021.12.28 |
| MLflow.5.Model Registry (0) | 2021.12.27 |
| MLflow.4.Tracking Server (0) | 2021.12.27 |
| MLflow.3.Experiments & Runs (0) | 2021.12.24 |