# 파이썬 버전 확인
$ python --version
Python 3.8.7
# mlflow 설치 & 버전 확인
$ pip install mlflow
$ mlflow --version
mlflow, version 1.16.0
# 예제 파일을 위한 mlflow repo clone
$ git clone https://github.com/mlflow/mlflow.git
$ cd mlflow/examples
Experiments & Runs
개념
MLflow에는 크게 실험(Experiment)와 실행(Run)이라는 개념이 있다. 실험은 하나의 주제를 가지는 일종의 '프로젝트'라고 보면 된다. 실행은 이 실험 속에서 진행되는 '시행'이라고 볼 수 있다. 하나의 실험은 여러 개의 실행을 가질 수 있다.
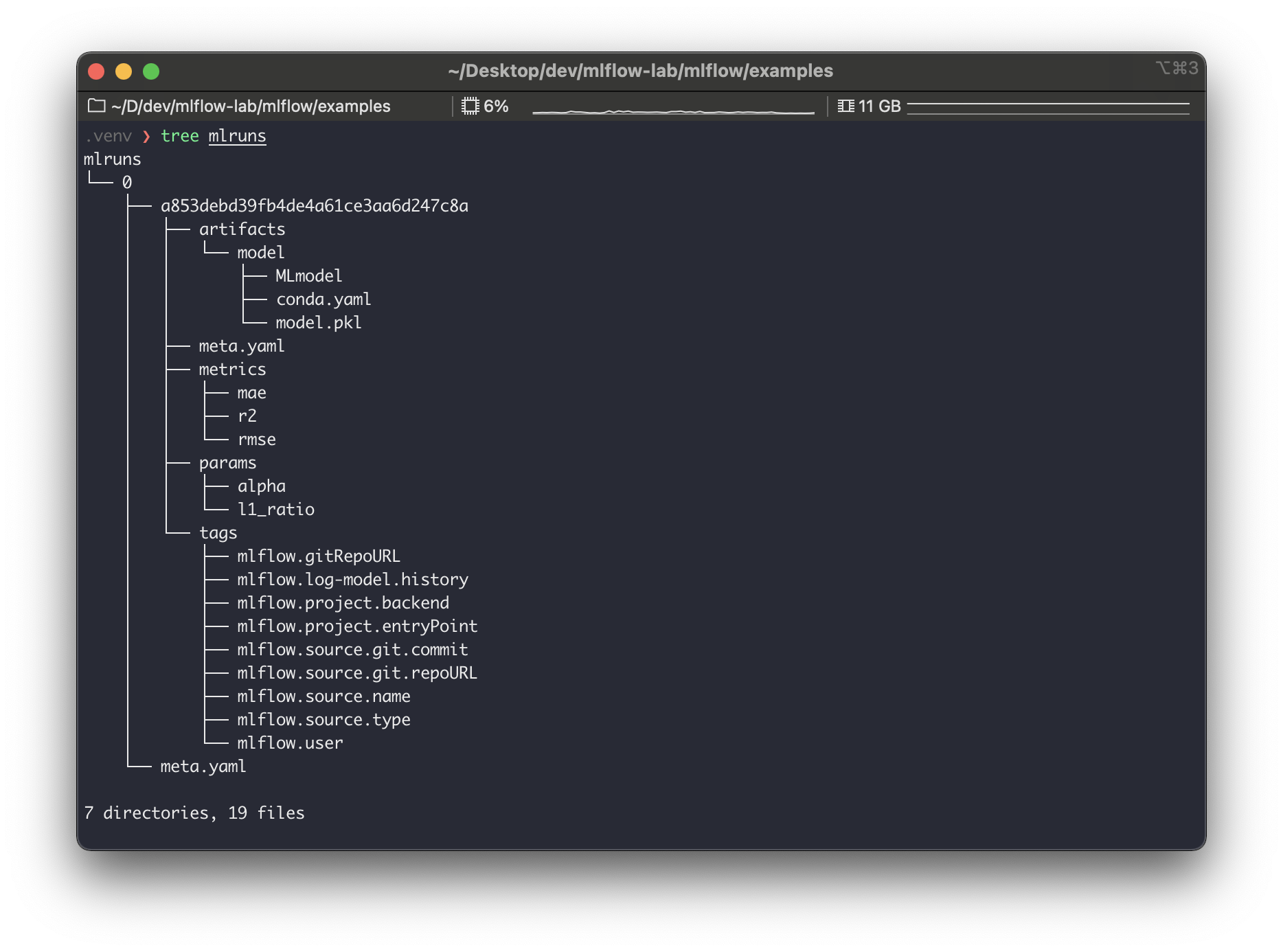
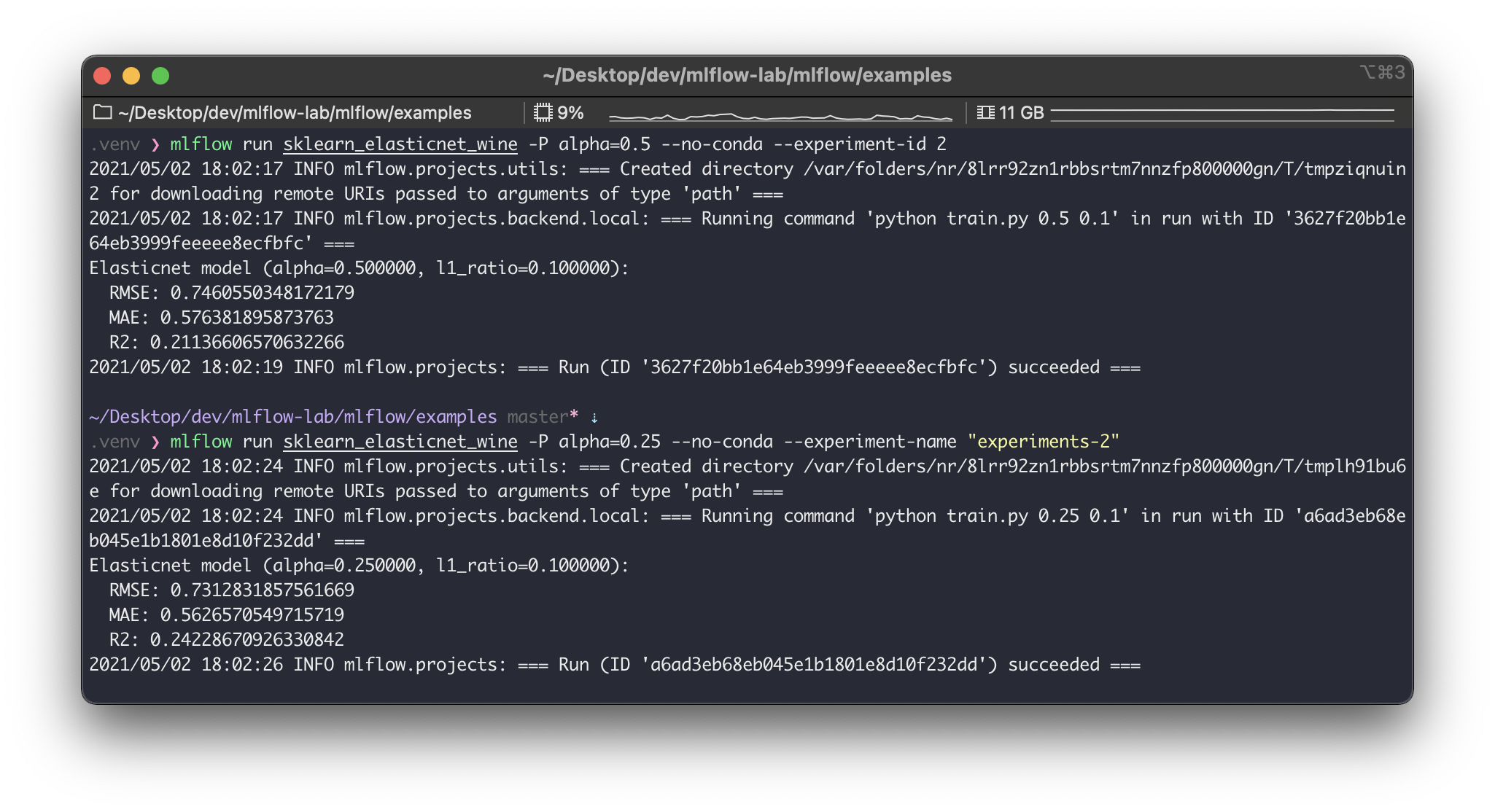
여기서0은 실험 ID이고,a853debd39fb4de4a61ce3aa6d247c8a은 실행 ID다. 한번 더 동일한 프로젝트를 실행해보자. 이번에는 파라미터 값을 추가로 넘겨줘본다.
$ mlflow run sklearn_elasticnet_wine -P alpha=0.5 --no-conda
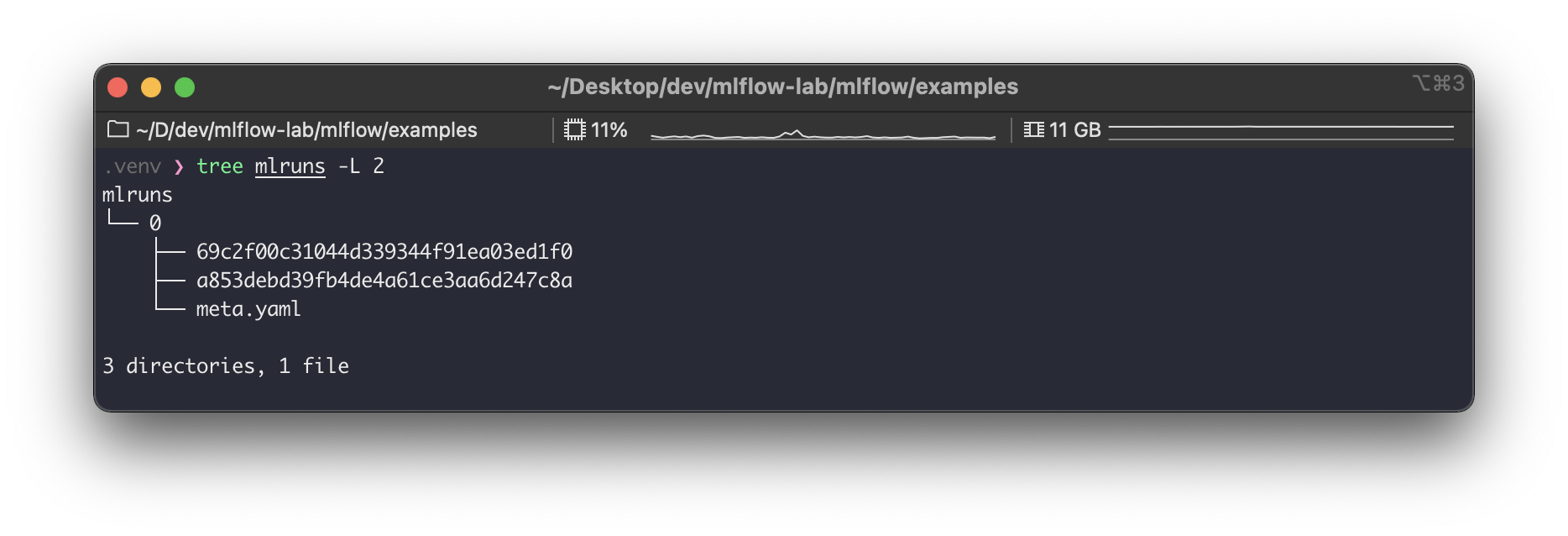
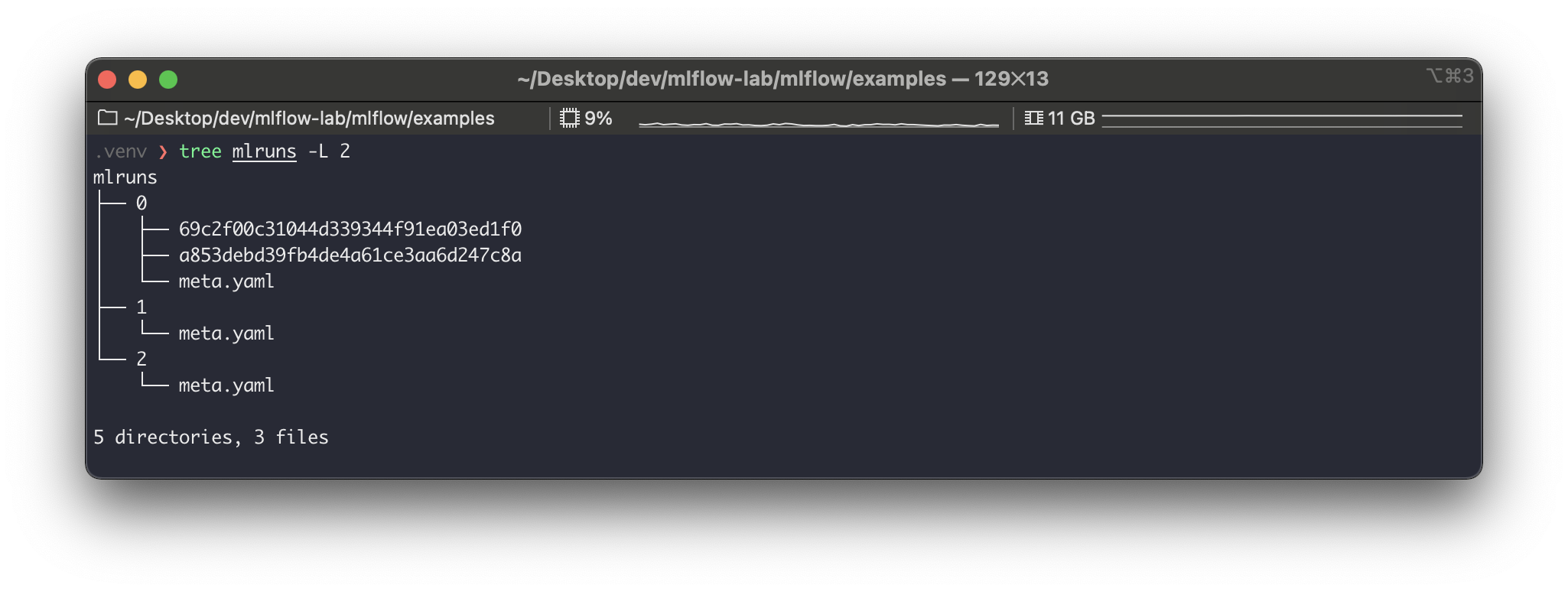
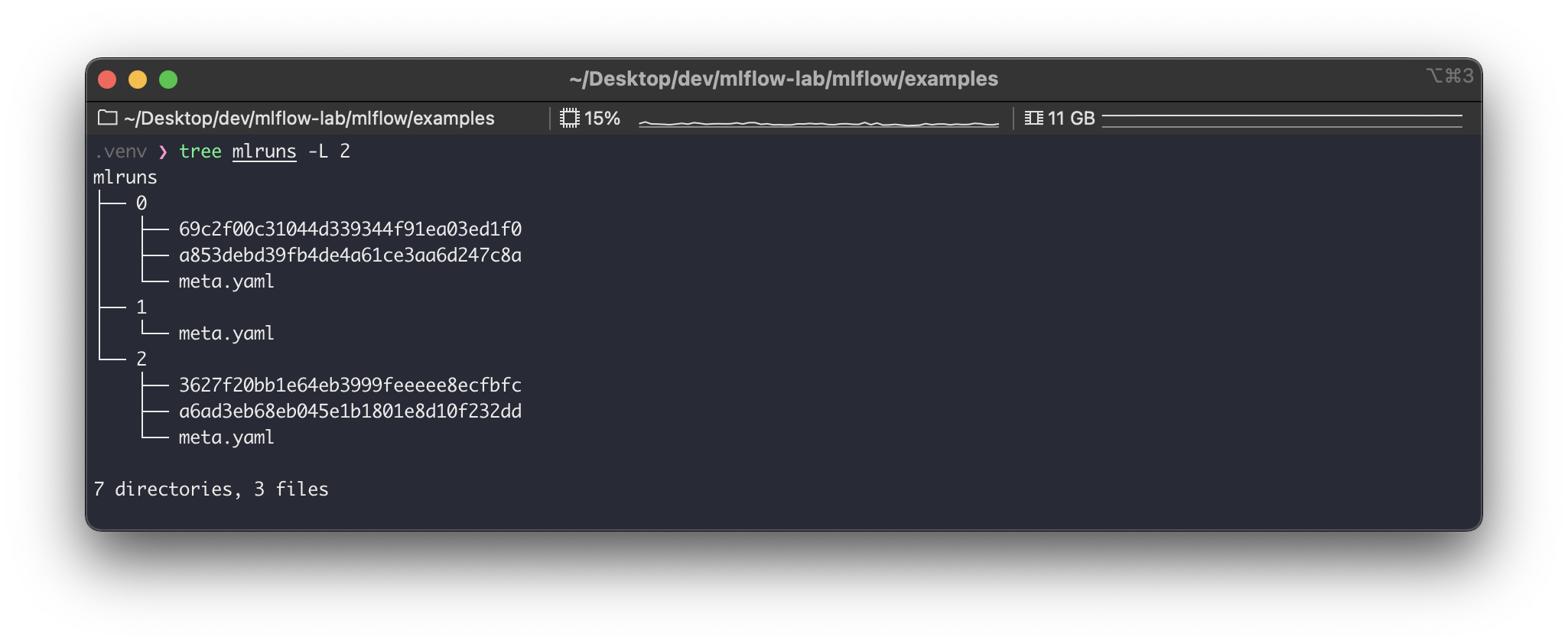
실행 결과로mlruns경로를 확인해보면 다음과 같다.
0이라는 실행에69c2f00c31044d339344f91ea03ed1f0이라는 실행이 추가로 생성되었다. 이렇듯 매 실행은 하나의 실험에 속하여 들어간다. 위의 예시가 매우 직관적이라 실험과 실행의 관계와 활용 방안을 바로 알 수 있을 것이다.
Experiment 생성 및 조회
위에서 별도의 실험을 생성하지 않았기 때문에 ID가0인 실험을 자동으로 생성하고 이 실험에서 실행을 생성하였다. 이번에는 직접 실험을 생성해보자.
실험 생성 은 다음 CLI 명령어로 가능하다.
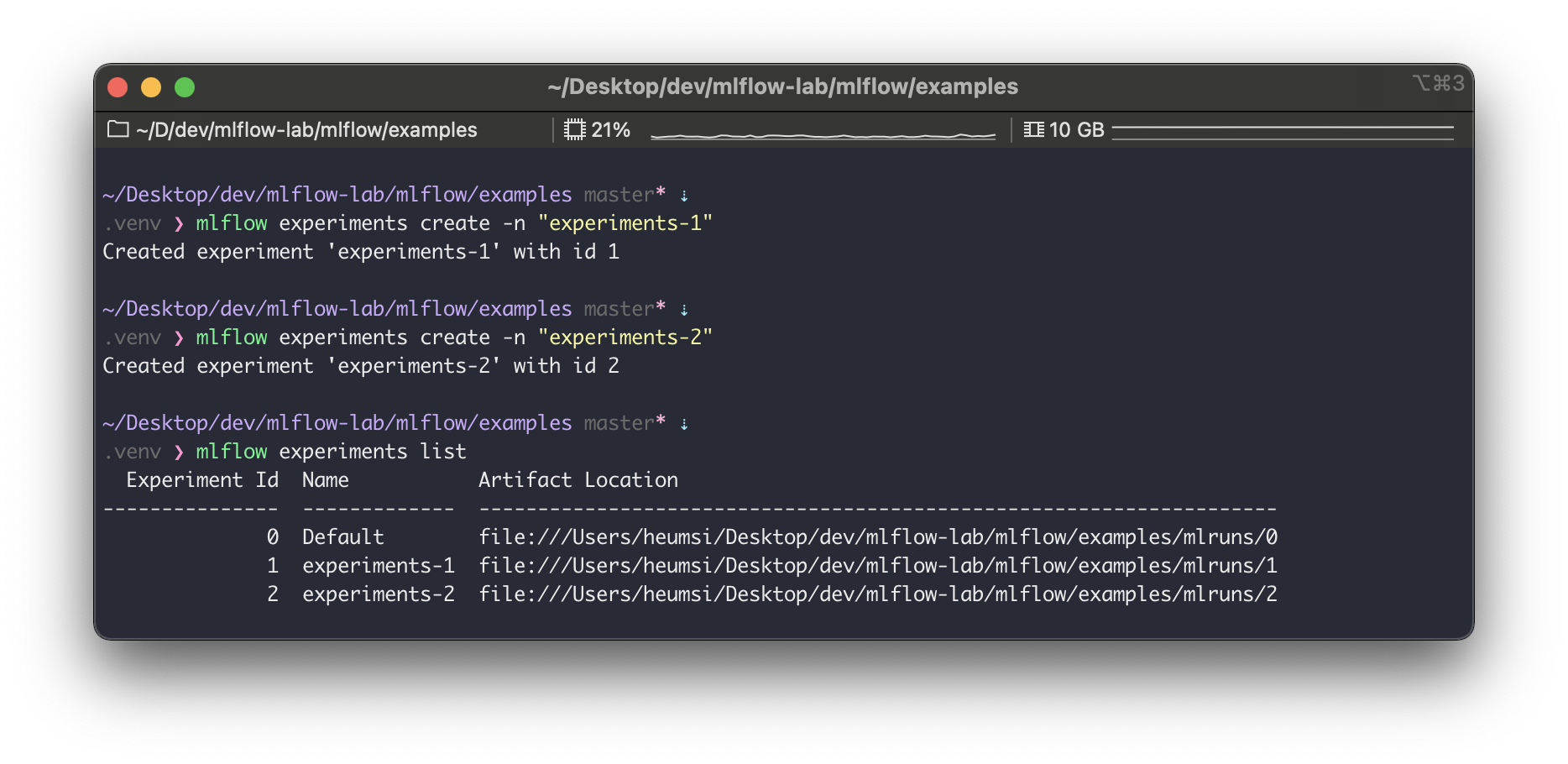
$ mlflow experiments create -n "실험 이름"
그리고 실험 목록은 다음 CLI 명령어로 가능하다.
$ mlflow experiments list
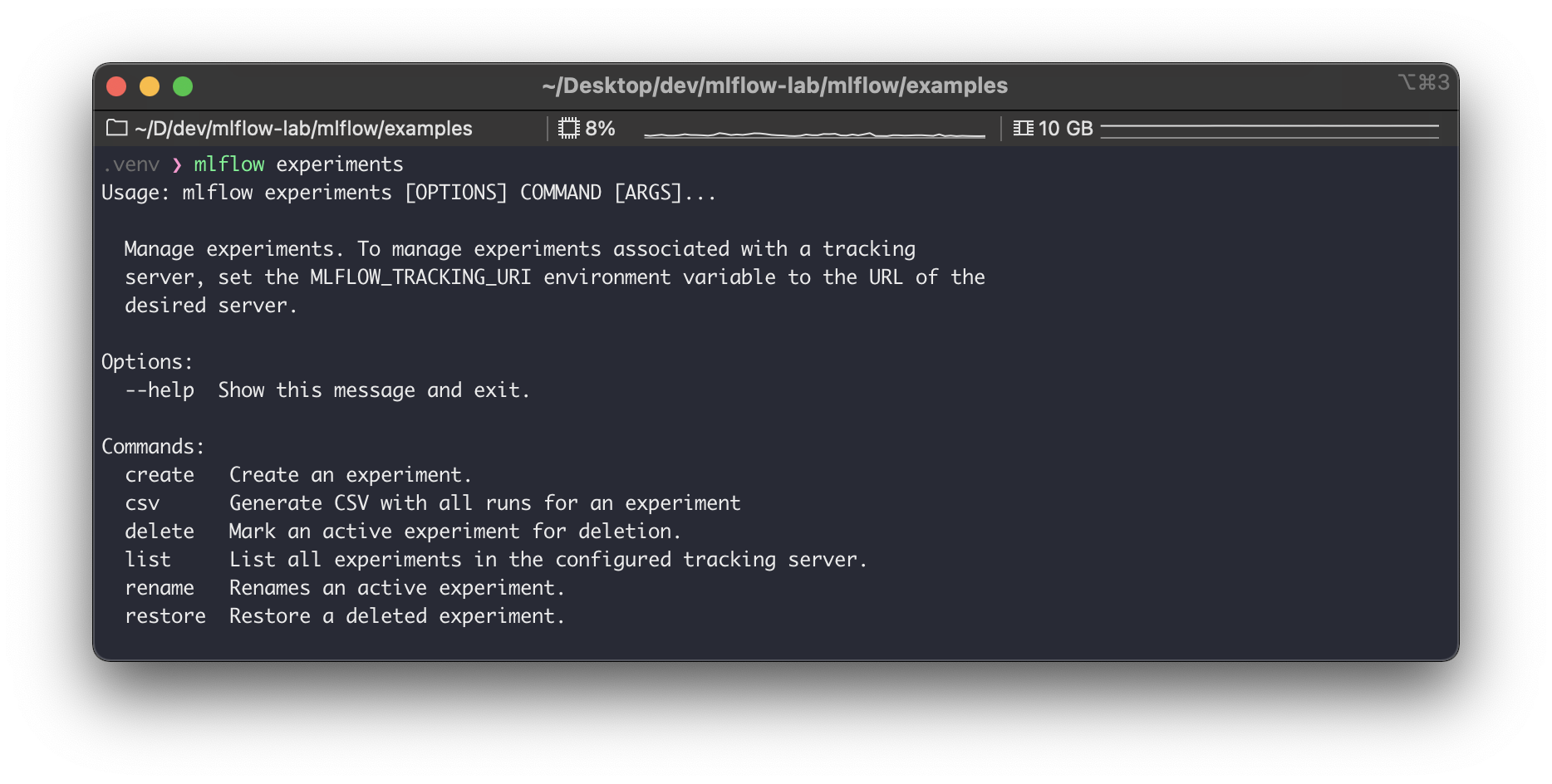
그 외mlflow experiments관련된 명령어는 다음의 것들이 있으니 참고하자.
CLI가 아닌 코드에서 experiments 및 run을 다루는 방법
다음처럼mlflow.tracking.MlflowClient를 사용하면 된다.
from mlflow.tracking import MlflowClient
# Create an experiment with a name that is unique and case sensitive.
client = MlflowClient()
experiment_id = client.create_experiment("Social NLP Experiments")
client.set_experiment_tag(experiment_id, "nlp.framework", "Spark NLP")
# Fetch experiment metadata information
experiment = client.get_experiment(experiment_id)
print("Name: {}".format(experiment.name))
print("Experiment_id: {}".format(experiment.experiment_id))
print("Artifact Location: {}".format(experiment.artifact_location))
print("Tags: {}".format(experiment.tags))
print("Lifecycle_stage: {}".format(experiment.lifecycle_stage))
저번 Quick 리뷰 글에 이어 계속해서 작성한다. 이번 글은 MLflow 에서 제공하는 Automatic Logging 기능 예제들을 살펴본다.
사전 준비
다음이 사전에 준비 되어 있어야 한다.
# 파이썬 버전 확인
$ python --version
Python 3.8.7
# mlflow 설치 & 버전 확인
$ pip install mlflow
$ mlflow --version
mlflow, version 1.16.0
# 예제 파일을 위한 mlflow repo clone
$ git clone https://github.com/mlflow/mlflow.git
$ cd mlflow/examples
예제 살펴보기
linear_regression.py
examples내에 있는 많은 예제 중,skelarn_autolog를 사용해보자. 먼저sklearn을 설치해준다.
# sklearn 설치 & 버전 확인
$ pip install sklearn
$ python -c "import sklearn; print(sklearn.__version__)"
0.24.2
skelarn_autolog/linear_regression.py를 보면 다음처럼 생겼다.
# skelarn_autolog/linear_regression.py
from pprint import pprint
import numpy as np
from sklearn.linear_model import LinearRegression
import mlflow
from utils import fetch_logged_data
def main():
# enable autologging
mlflow.sklearn.autolog()
# prepare training data
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# train a model
model = LinearRegression()
with mlflow.start_run() as run:
model.fit(X, y)
print("Logged data and model in run {}".format(run.info.run_id))
# show logged data
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} - ---------".format(key))
pprint(data)
if __name__ == "__main__":
main()
소스코드가 아주 간결하고 잘 설명되어 있다. 내용은 Linear Regression을 사용하는 간단한 머신러닝 코드다. 여기서는 2가지 코드가 눈에 띈다.
mlflow.sklearn.autolog()
Automatic Logging 기능을 사용하는 설정이다.
코드 앞부분에 들어가야 한다.
with mlflow.start_run() as run:
MLflow 의 실행(run) 의 시작을 알리는 컨텍스트 매니저 구문이다.
run에는 실행과 관련된 내용이 들어간다.
이제 다음 명령어로 실행해보자.
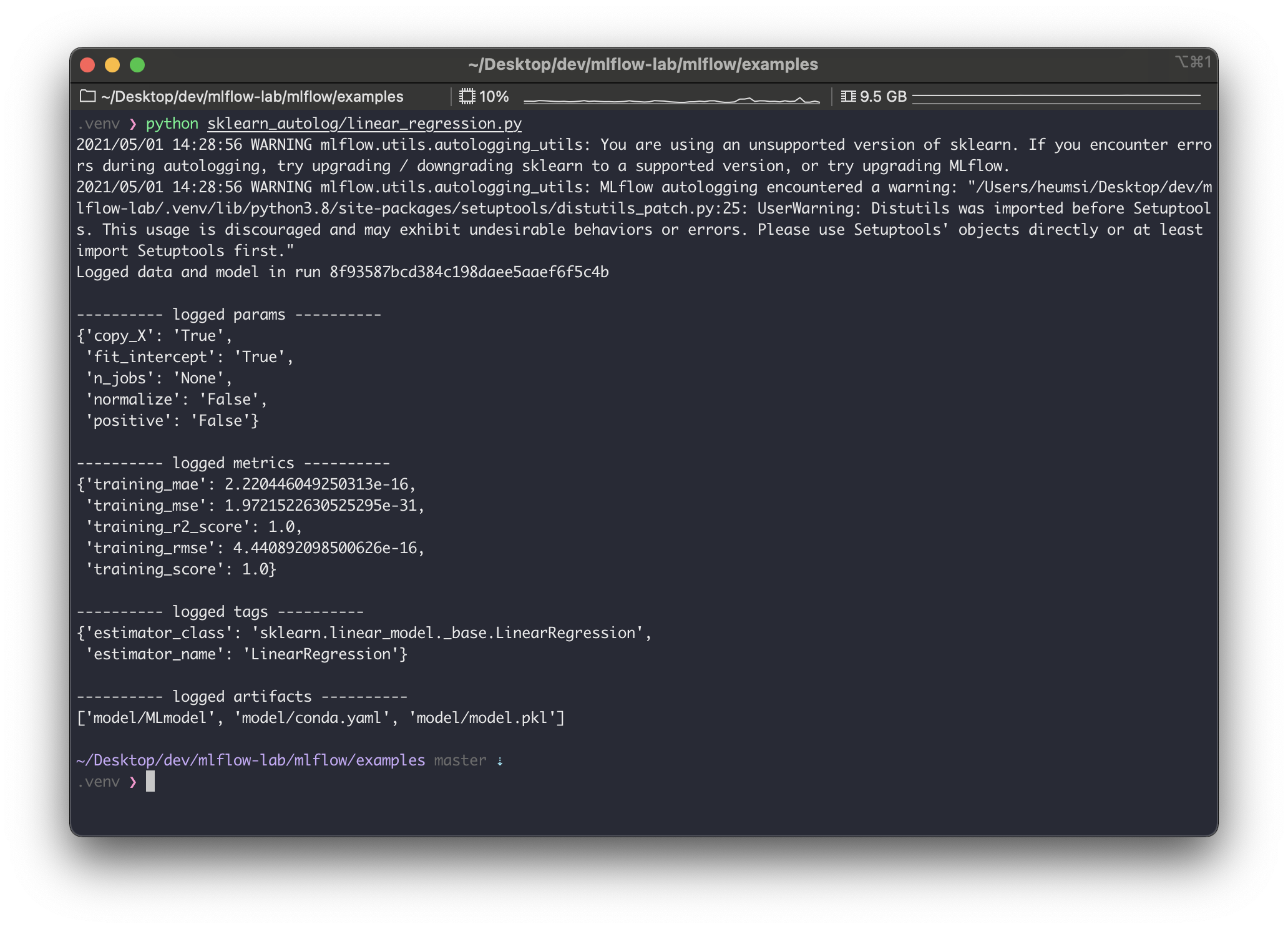
$ python sklearn_autolog/linear_regression.py
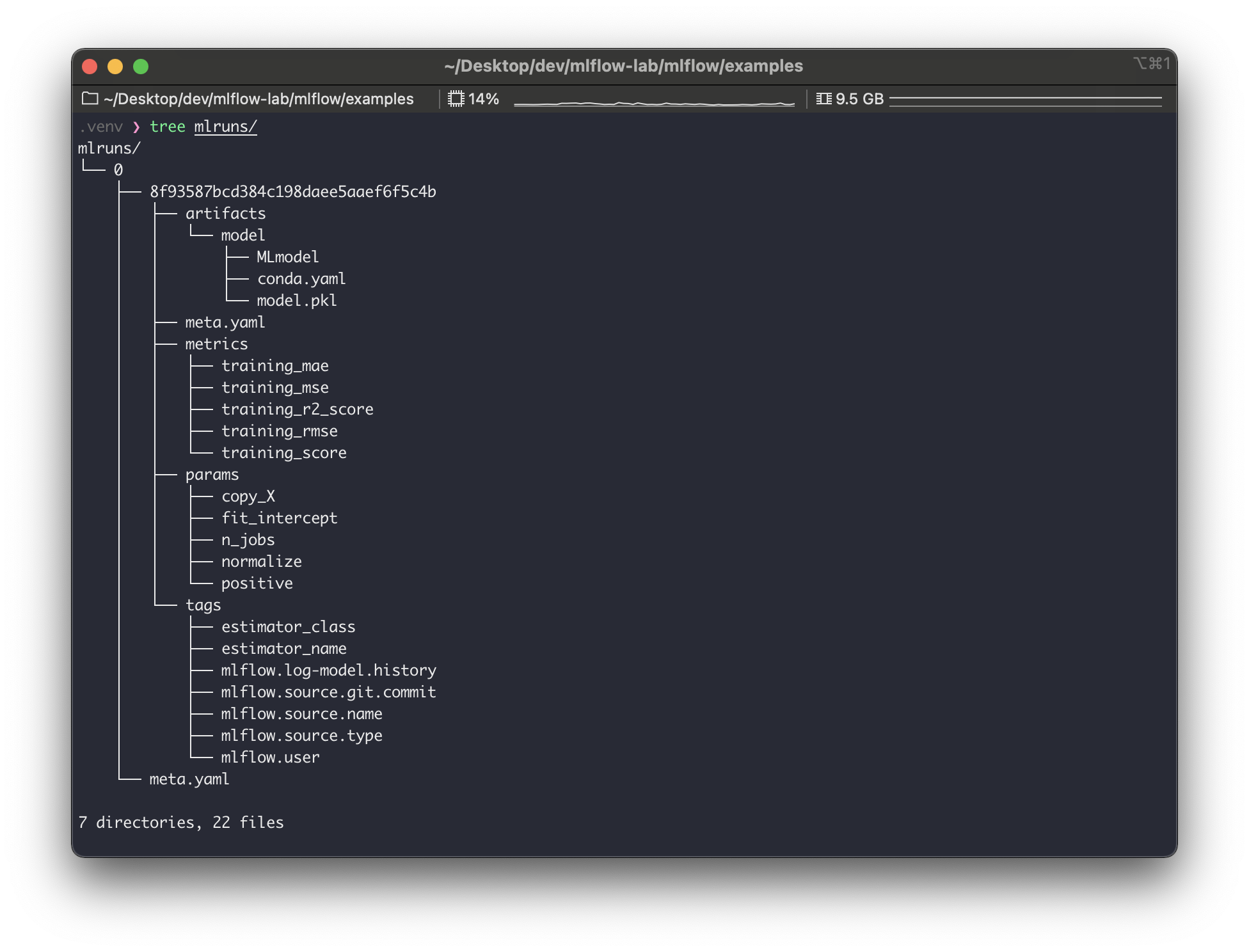
실행하고 나면 위와같은 출력이 나온다. warning은 일단 무시하면 될듯하고.. 로그를 좀 살펴보면,run_id가8f93587bcd384c198daee5aaef6f5c4b로 생성되었고, 다음 사항들이 자동으로 기록한 것을 알 수 있다.
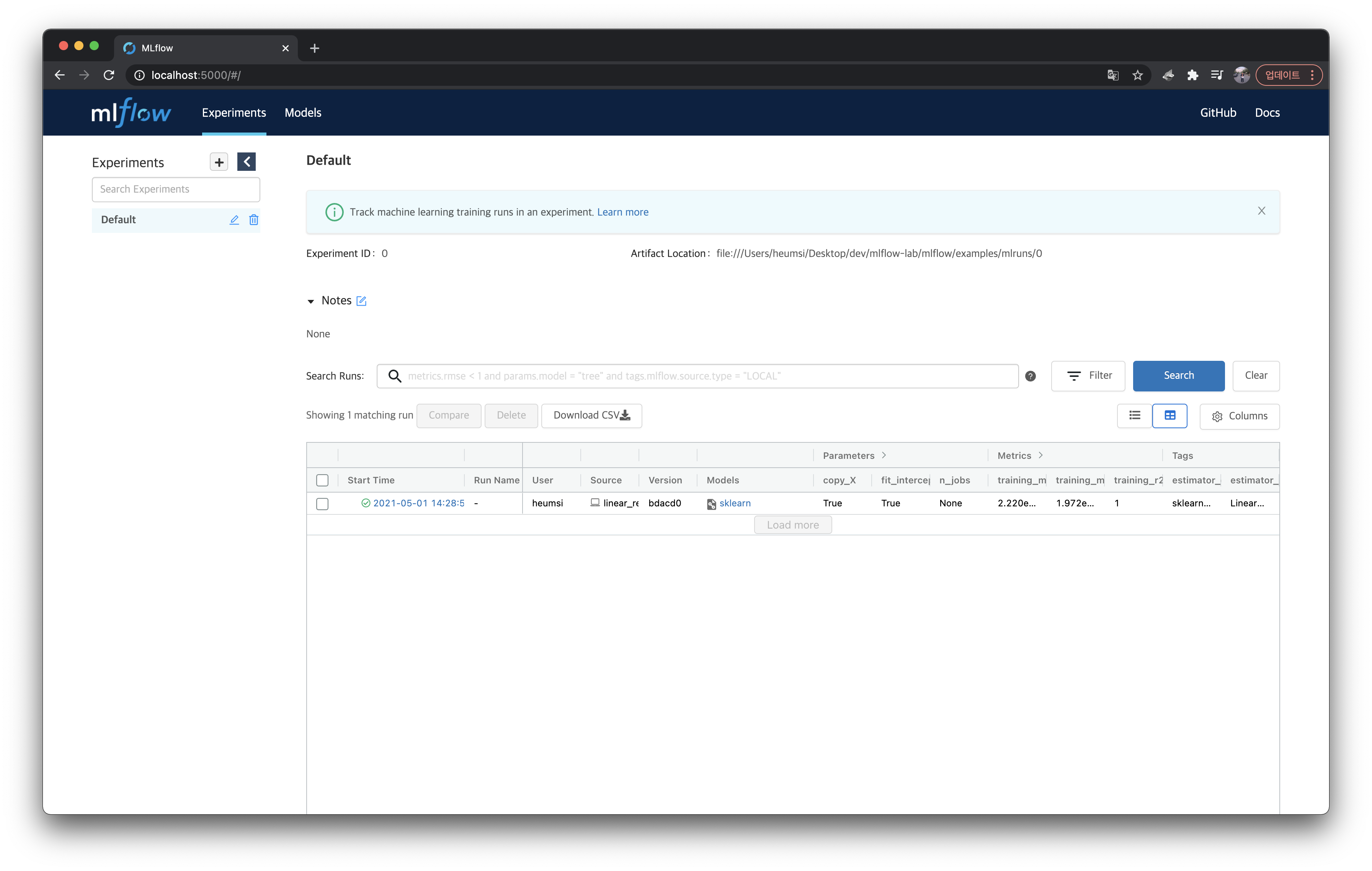
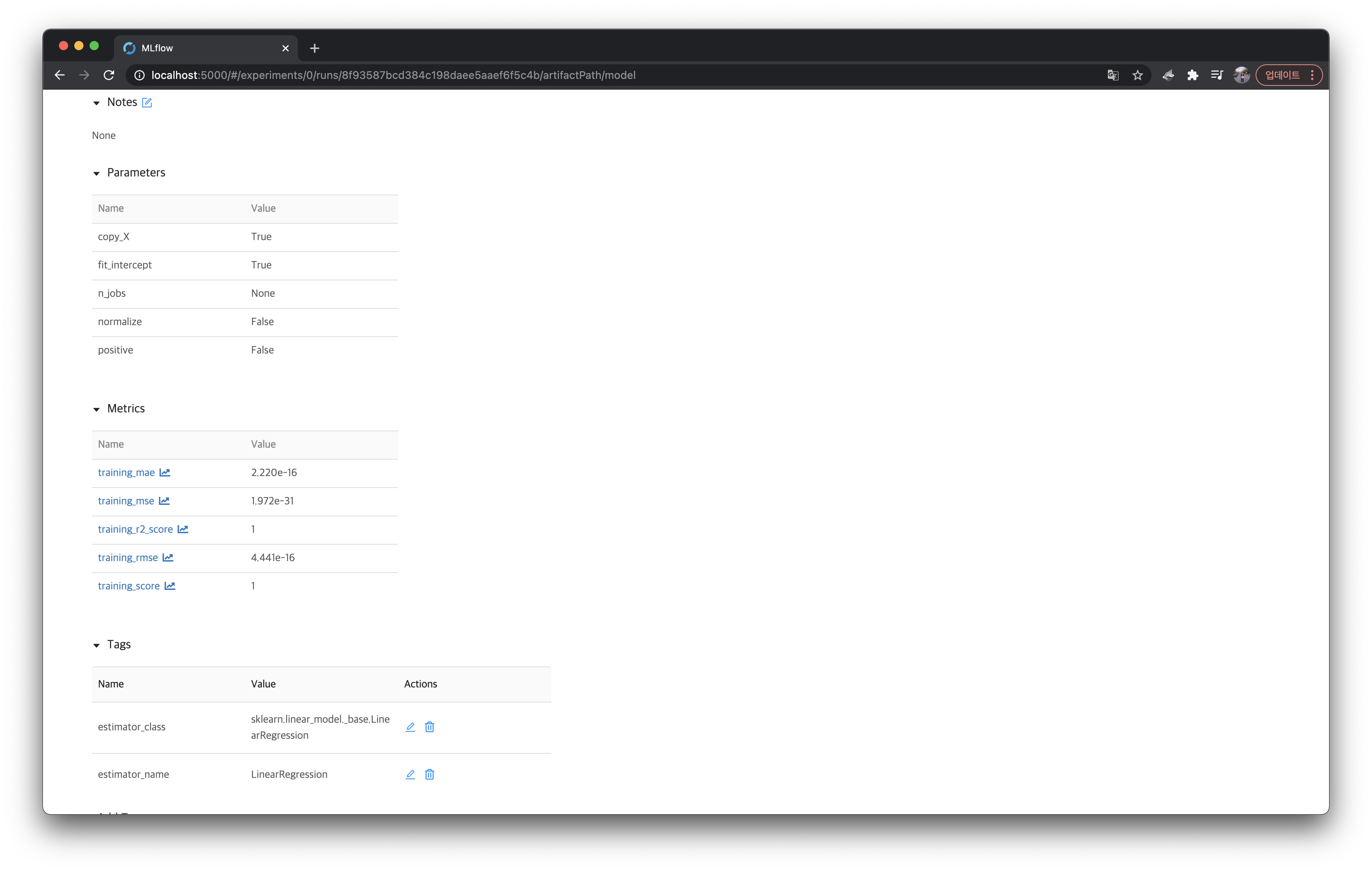
params,metrics,tags등을 좀 더 자세히 확인해보기 위해sklearn모델을 클릭하여 실행 상세 페이지에 들어가보자.
위에서 출력한 내용들이 모두 잘 들어가있는 것을 볼 수 있다.
pipeline.py
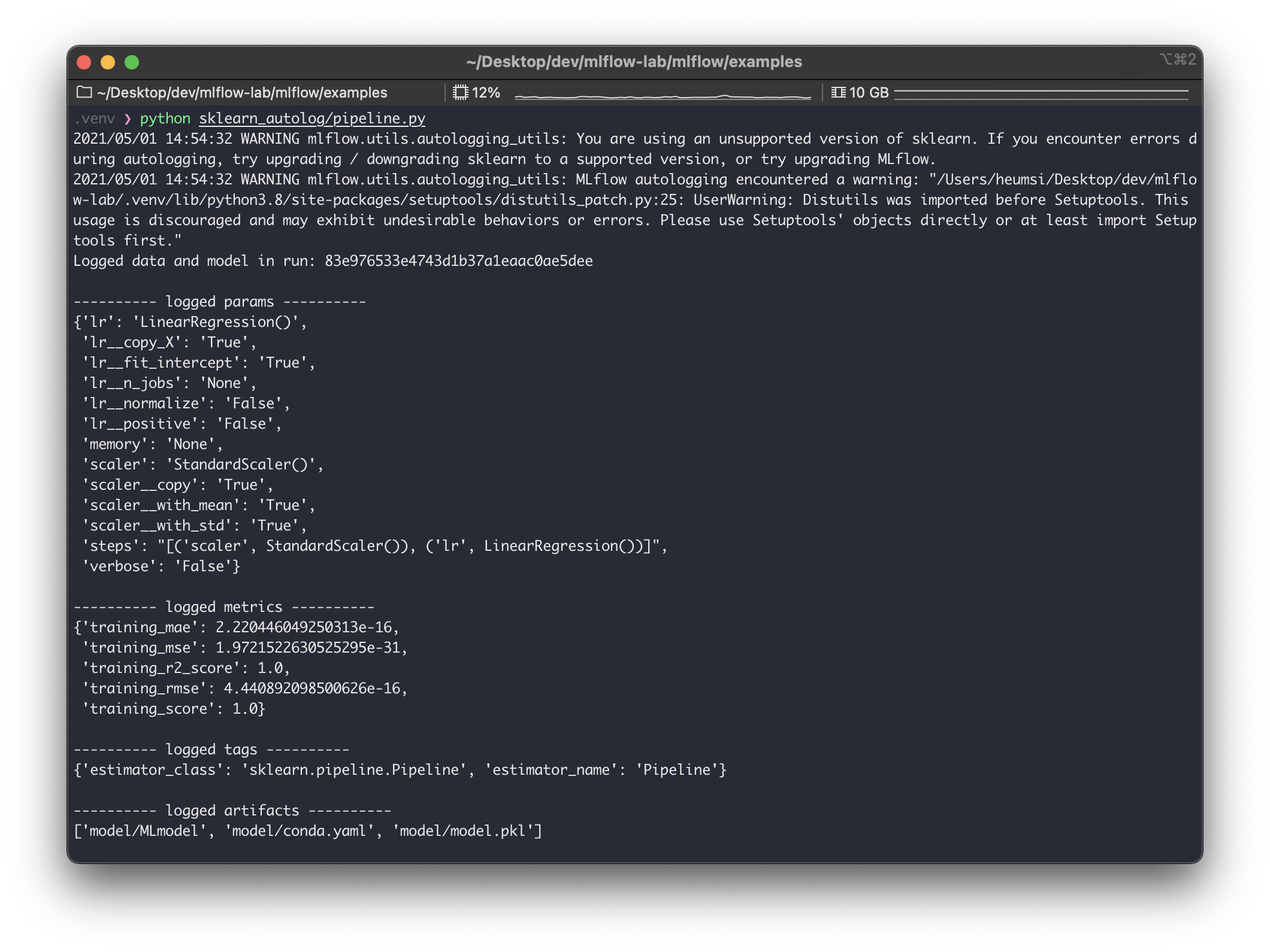
이번엔skelarn_autolog/pipeline.py예제를 살펴보자. 이 파일은 다음처럼 생겼다.
from pprint import pprint
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import mlflow
from utils import fetch_logged_data
def main():
# enable autologging
mlflow.sklearn.autolog()
# prepare training data
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# train a model
pipe = Pipeline([("scaler", StandardScaler()), ("lr", LinearRegression())])
with mlflow.start_run() as run:
pipe.fit(X, y)
print("Logged data and model in run: {}".format(run.info.run_id))
# show logged data
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} ----------".format(key))
pprint(data)
if __name__ == "__main__":
main()
sklearn.pipeline.Pipeline을 사용하는 간단한 머신러닝 코드다. 바로 실행해보자.
$ python sklearn_autolog/pipeline.py
logged_params를 보면Pipeline에 들어가는 모든 파라미터를 기록하는 것을 볼 수 있다. 기록된 값 역시mlruns/에 저장된다.
grid_search_cv.py
마지막으로,skelarn_autolog/grid_search_cv.py예제를 살펴보자. 다음처럼 생겼다.
from pprint import pprint
import pandas as pd
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
import mlflow
from utils import fetch_logged_data
def main():
mlflow.sklearn.autolog()
iris = datasets.load_iris()
parameters = {"kernel": ("linear", "rbf"), "C": [1, 10]}
svc = svm.SVC()
clf = GridSearchCV(svc, parameters)
with mlflow.start_run() as run:
clf.fit(iris.data, iris.target)
# show data logged in the parent run
print("========== parent run ==========")
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} ----------".format(key))
pprint(data)
# show data logged in the child runs
filter_child_runs = "tags.mlflow.parentRunId = '{}'".format(run.info.run_id)
runs = mlflow.search_runs(filter_string=filter_child_runs)
param_cols = ["params.{}".format(p) for p in parameters.keys()]
metric_cols = ["metrics.mean_test_score"]
print("\n========== child runs ==========\n")
pd.set_option("display.max_columns", None) # prevent truncating columns
print(runs[["run_id", *param_cols, *metric_cols]])
if __name__ == "__main__":
main()
iris데이터셋을 사용하고,svm모델을 사용하는데, 이 때GridSearchCV를 사용하여 최적의 모델 파라미터를 찾는 머신러닝 코드다. # show data logged in the parent run아래 부분은 뭔가 양이 많은데, 그냥 로깅된 내용을 출력해주는 부분이므로, 여기서는 주의 깊게 봐지 않아도 된다.
아무튼 이 코드도 실행해보자.
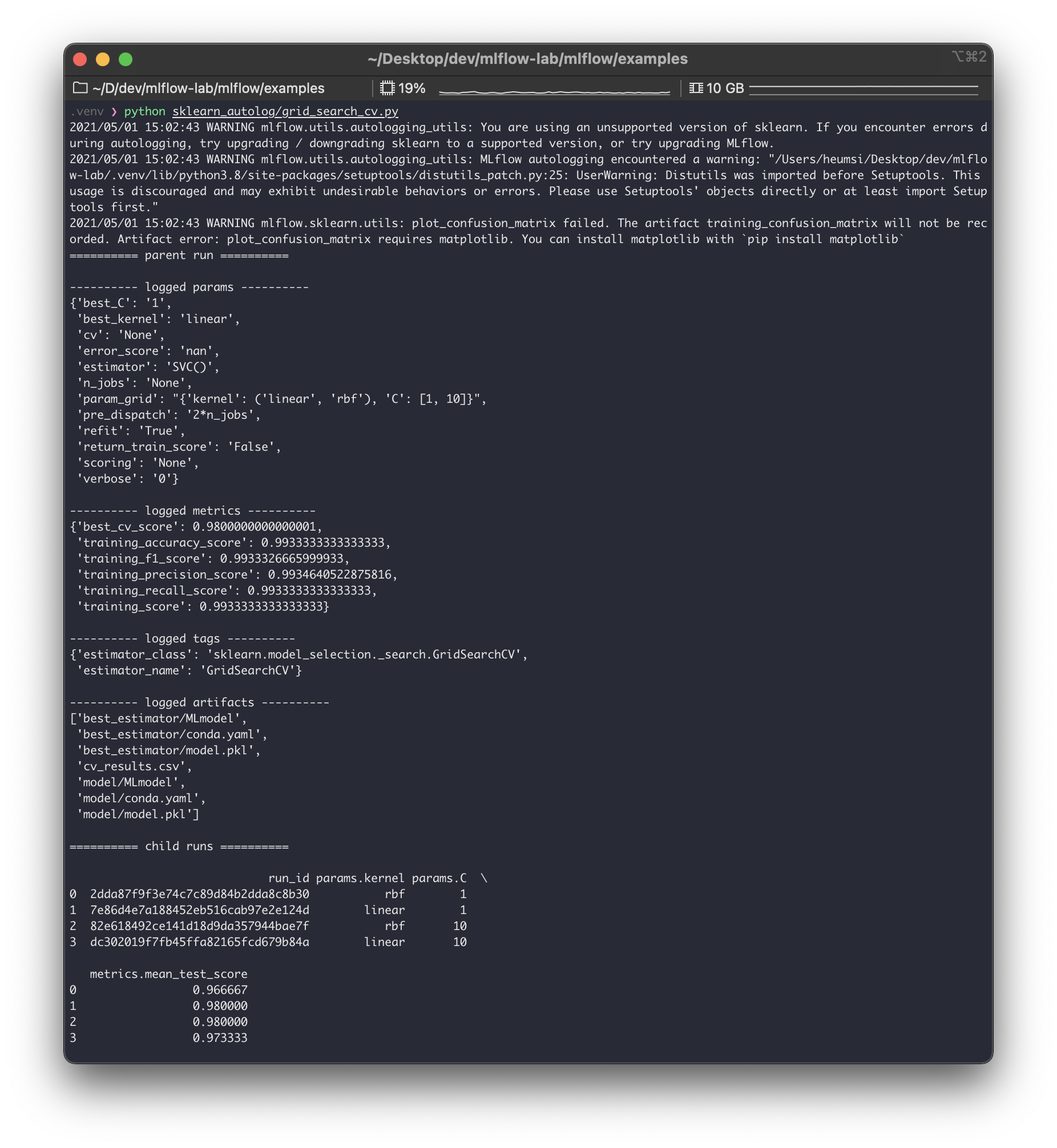
$ python sklearn_autolog/grid_search_cv.py
출력된 내용을 보면 크게parent run과child runs으로 구성해볼 수 있다. parent run에서는 전체 파이프라인에 들어간 파라미터 값들을 기록하고, 또 이GridSearch를 통해 찾은 최적의 파라미터 값을 기록한다. (best_C,best_kernel). child runs에서는GridSearch진행할 때 각각 파라미터 경우의 수대로run들을 실행하고 기록한 모습을 볼 수 있다. 이 때child runs들도 각각 하나의run이 되므로run_id를 가지게 된다. 즉GridSearch에서 파라미터 조합의 경우의 수가 많아지면, 그만큼의 실행(run) 이 생기게 된다.
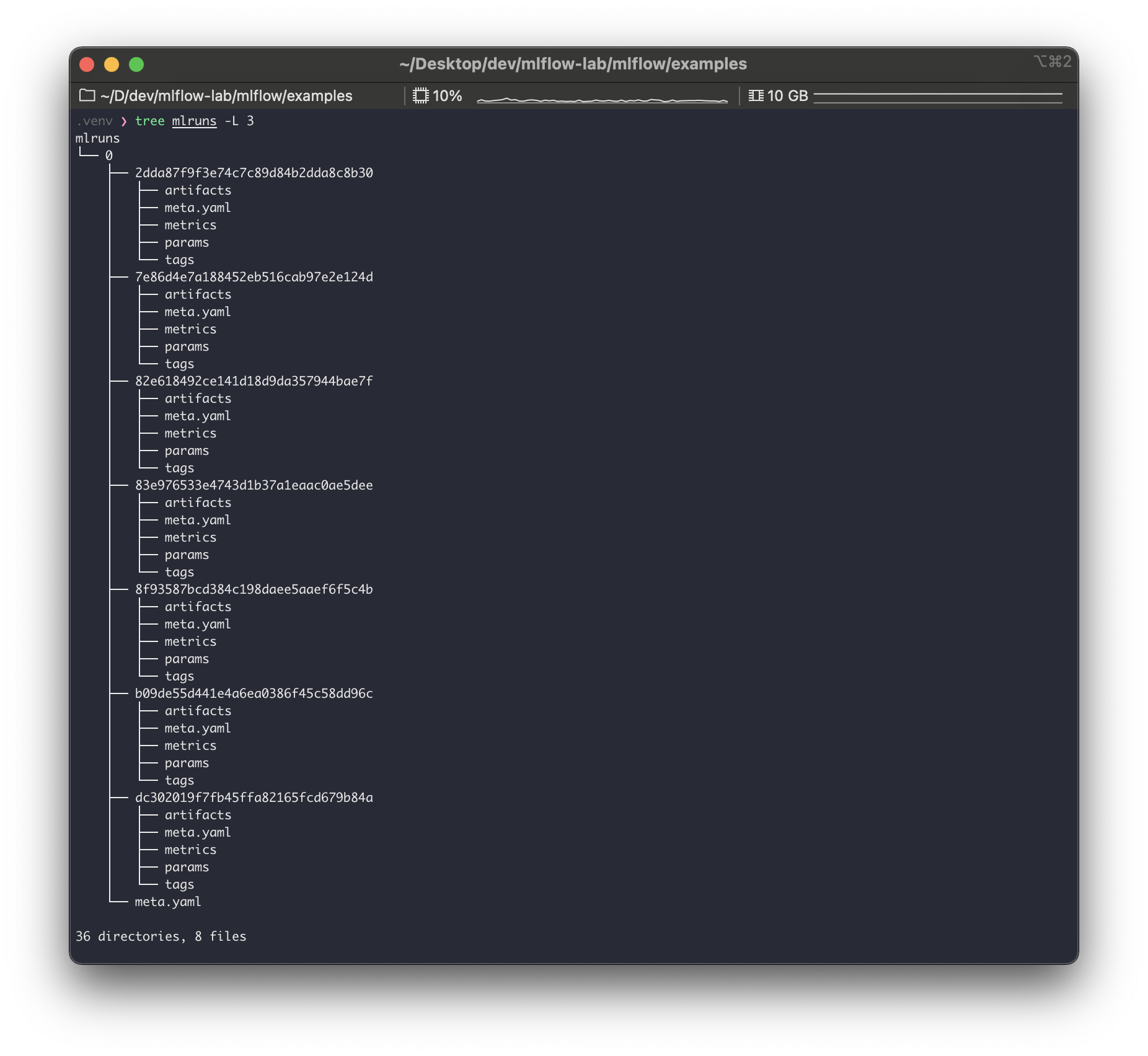
실제mlruns를 확인해보면 이child run들이 생긴 것을 볼 수 있다. (다만parent run과 별다른 디렉토리 구분은 없다. 즉 누가child run인지 디렉토리 구조로는 파악이 잘 안된다.)
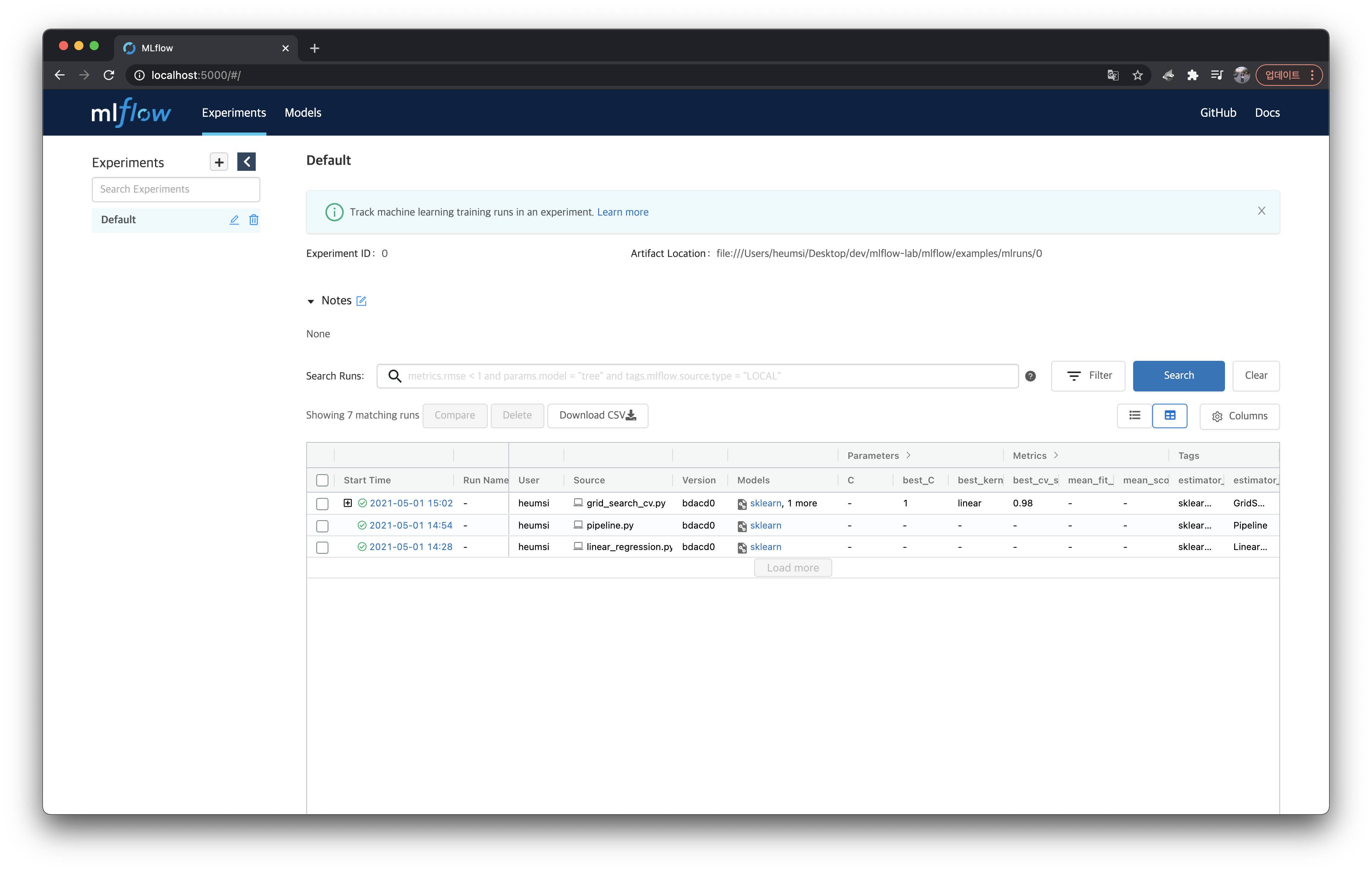
그렇다면 웹서버에서는 어떻게 보여줄까? 웹서버에서도child run들을parent run들과 구분 없이 보여줄까? 이를 확인하기 위해 웹서버로 접속해서 확인해보자.
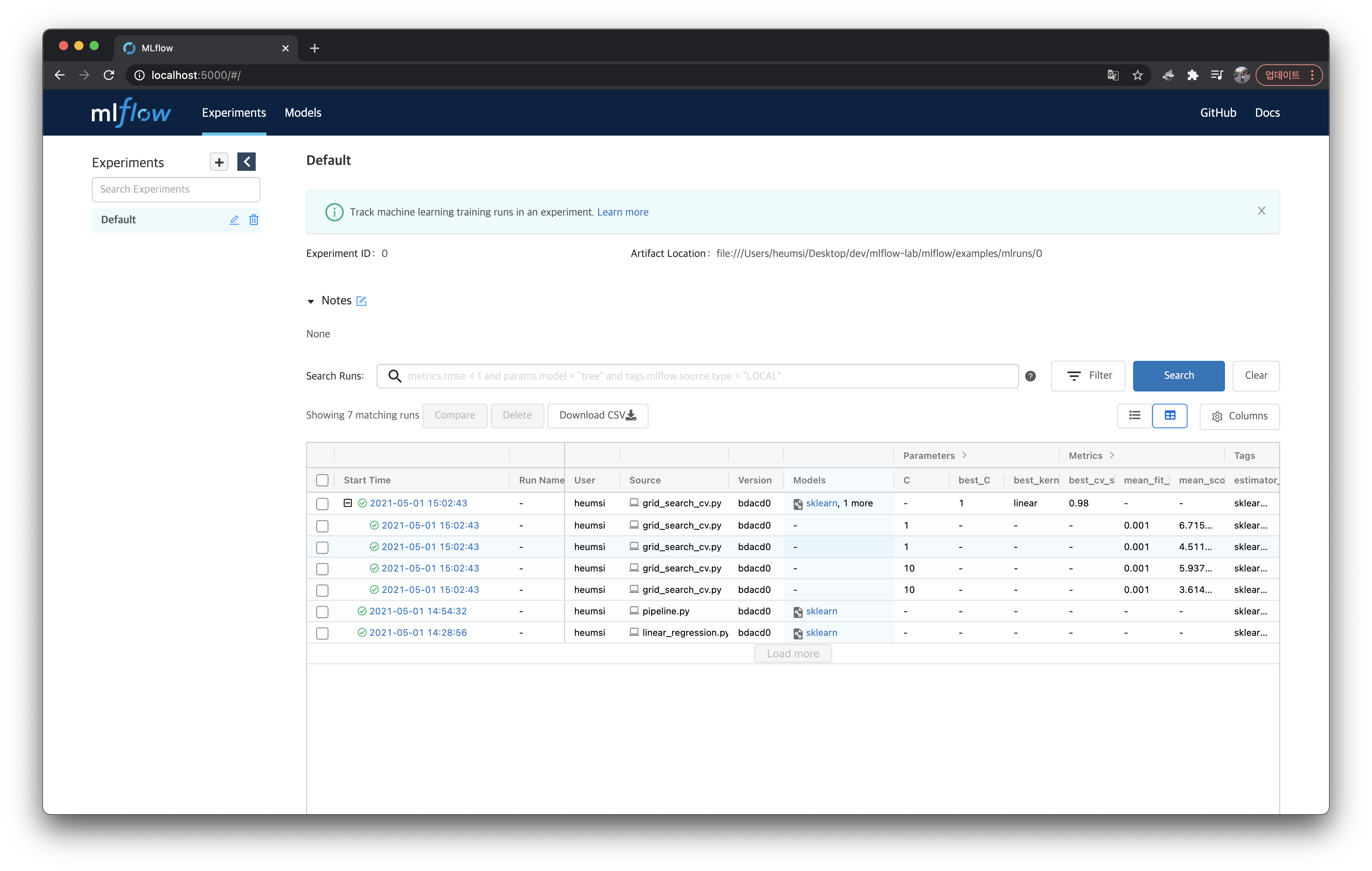
재밌게도 웹서버에서는parent run만 보인다. grid_search_cv.py가 있는 행에+버튼을 눌러보면 아래와 같이child runs가 나온다.
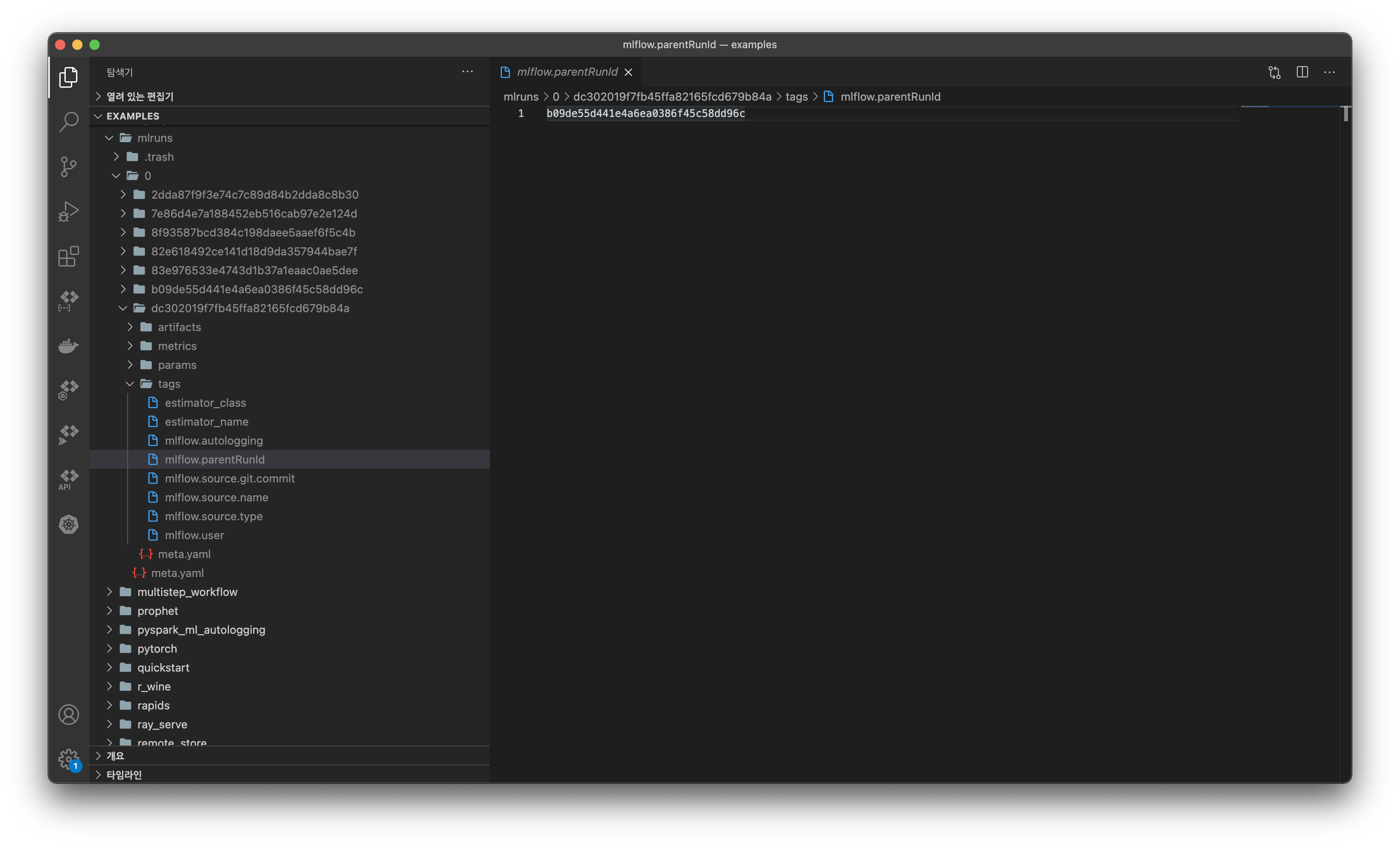
run자체는GridSearch에 맞게 독립적으로 여러 개로 생성하되,run간에 Parent, Child 관계를 가질 수 있는 것이다. parent_run_id로mlruns디렉토리를 검색해보면, 이러한 관계가 어떻게 구성될 수 있는지 알 수 있다.
mlruns에서child run의 디렉토리 구조를 살펴보면tags/mlflow.parentRunId가 있는 것을 볼 수 있다. 그리고 이 파일에 위 사진처럼 부모run_id가 기록되어 있다. (b09de55d441e4a6ea0386f45c58dd96c는dc302019f7fb45ffa82165fcd679b84a의parent run이다.)
그리고child run은artifact과 관련하여 어떤 것도 기록하지 않고,metrics,params,tags만 기록한다.artifacts는 최종적으로 최적화된 모델을 사용하는parent run에서만 기록한다.
정리
mlflow.sklearn.autolog()기능으로 로깅 함수를 쓰지 않아도 자동 로깅을 사용할 수 있다.